 freebuf
freebuf原创: Smity 合天智汇
本文所有代码都已经发布在github项目主页上
https://github.com/smityliu/spider
微博模拟登录、推特模拟登录
久等了各位伙伴们,本篇文章是我们社交网络人物画像的第三篇,也是我们爬虫最技术含量最为丰富的一篇,之前的两篇文章基于社交网络爬虫分析人物兴趣属性(一);基于社交网络爬虫分析人物兴趣属性(二)发表了以后,有师傅问过我为什么不做一下模拟登录,会比较好,然后也给了我很多建议,比如如何做数据对齐的建议,看来其实人物画像真的很多师傅有经验,现在大公司也做大数据分析的工作。
我没有直接公开模拟登录的研究过程是因为之前爬虫违规使用的问题闹得沸沸扬扬,所以我不太想在公开平台讨论国内的社交网络,但是后来看见大部分的论坛其实都有公开了新浪微博或者知乎一类的模拟登录,并且我也询问了很多白帽子的同僚,知道了其实正常使用模拟登录是允许的。下面就来进入今天大家都很想看的主题——新浪微博模拟登录和推特模拟登录。
为什么需要这个呢,因为我们遇到了两个问题:
1. 我们之前只选取了一个社交网络,数据偶然性太大了,得选取两个——微博和推特
2. 两个网路哦就必须要做数据对齐,如何保证你做数据融合的两个用户是同一个人,必须得找到相关得信息
在数据对齐的时候要搜索足够多的用户相关信息,其中某用户关注的人员就是很重要的一块,但是我们如果不登陆是看不到他们的关注的:

在讲模拟登录之前我们必须要做一个事情,就是明确登录后我们要干嘛——爬取用户的关注。
那么这里就会有一个问题:爬一个够吗,肯定不够,我们需要爬好几层。什么叫做好几层呢?就是递归爬取,递归之前我们需要确定“种子”和“层数”:
比如,确定种子为娱乐圈的10个人
孙燕姿,郭德纲,周润发,朱茵,宋丹丹,冯小刚,科比,乔丹,刘翔,泰勒斯威夫特,贾斯汀比伯,甄子丹,成龙,张纪中
确定理由,包含了导演,影视圈演员,歌手,艺术家,国外歌手,体育明星,其中歌手包含老一辈和新一代,并且是个种子里面都有互相关联的人
每个种子都爬取两层关注,就是他自己这一层,加上他关注的人的关注,基本可以做到覆盖所有的娱乐圈,微博两层拓展后的总数据量有1万多人,推特少一些,但是也有大概3,4千人左右
这个地方有三个单位:- 1. 每层
- 2. 每层的个人
- 3. 每个人的关注**
按照优先级"每个人>每个人**>每一层>递归",就是先第1层第一个:[],然后获取这一个的**,然后第1层第二个:[],然后回去这一个的**...... 这一层的每一个弄完以后,进行递归,然后再找第2层的第一个、第二个、第三个,以此类推。
理由:任何一个顺序颠倒都会增加运算量或者编程难度
1. 如果先弄一层再取每一个人的**,那么会多一次for循环遍历。
2. 如果每一个取完两层再换下一个,那么会多n的2次方运算,大家可以试试。
递归开始:
举个例子,冯小刚关注了吴京,吴京关注了胡歌,胡歌又关注了吴君如,吴君如又有很多香港明星的微博,导演这一层就可以拓展到所有演员
在演员中,只要有人关注了歌手,比如郑凯关注了黎明,那么黎明里的关注又会有一个上海合唱团他曾经指导过的团队,这个团队又会关注著名主持人何炅,何炅又关注了很多非演员歌手得明星比如岳云鹏,又会将影视圈演艺圈拓宽到综艺圈和相声界,然后在这些人中有一个关键节点金星老师,她关注了刘翔,从而拓展到了体育界,再拓展到国外。
之后的两个模拟登录,我们就直接把这个算法模型带入到爬虫中。
微博模拟登录
首先,明确一点——关于爬虫,“只要能够通过浏览器看到的,你肯定都能爬下来,只是难度不同”:
最难的爬虫:带验证码,目前识别验证码的库和爬虫都已经达到商业级别,确实很不好做或者每次爬取的成功几率都很小。
最简单的爬虫:没有任何验证机制,post传入用户名和密码到表单就直接可以获取cookie了。
我们先来看新浪微博:
可惜有验证码,那这个肯定工作量很大了,但是,上天还是照顾钻研的人,让我发现了一个绕过的地方:微博手机端
因为我自己也用微博,所以在手机上也安装了微博的app,用浏览器打开后,发现他的域名是这个:https://weibo.cn/pub/
很惊喜的地方在于
根本不需要验证码有木有!
所以很简单了,直接Burpsuite截取包:
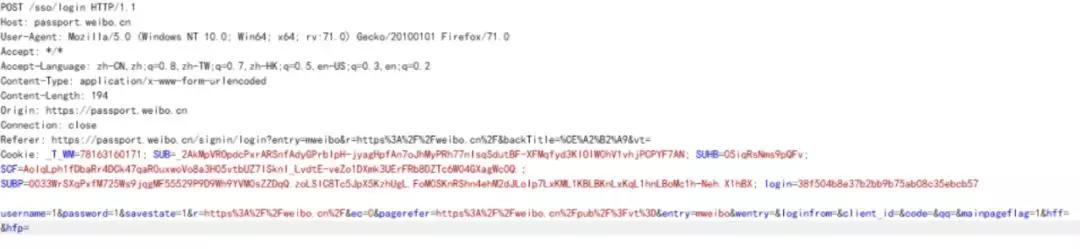
发现有一下几个字段(username,password,cookie已经被我删除):
headers={ 'Host': 'passport.weibo.cn', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0', 'Accept': '*/*', 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Content-Type': 'application/x-www-form-urlencoded', 'Origin': 'https://passport.weibo.cn', 'Connection': 'close', 'Referer': 'https://passport.weibo.cn/signin/login?entry=mweibotd valign="top">ahref="https://weibo.cn/u/2530520950">风吹铃铛响叮叮/a>然后访问这个主页会发现,在关注连接的地方有href连接,包含了id和关注页面的连接:
a href="/2530520950/follow">关注[583]/a>
所以我们的递归就是:
1. 爬取用户的关注列表
2. 从中提取每个用户的主页和昵称
3. 在主页中正则提取关注连接,获取id
4. 将所有id整合为list,作为下一次递归的输入
接下来我们导入递归算法,这里有几个坑,比如微博有反爬虫机制,如果你的请求速度过快,即使登录之后,他也会将你302重定向到security.api去,并且让你输入短信验证码,代码运行后是如下情况而不是登录失败。
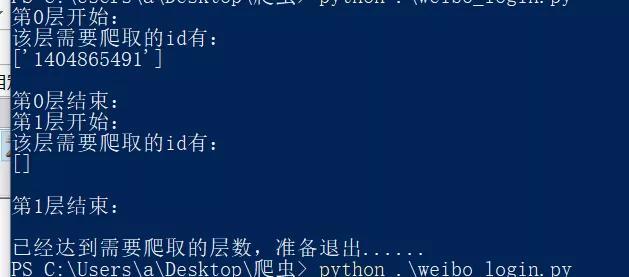
出现这样的情况不要怕,肯定是微博已经将你加入限制了,限制了你的免验证登录。解决办法:
1. 先去weibo.cn试试登录看,有没有要你验证身份,如果有,重新申请一个账户吧,这个是不会取消的重新,申请一个账户就可以免去检查。
2. 重新申请一个账户后,每一个账户尽量在固定ip下用同一种方式登录,也就是说,用脚本登录后,尽量不要太频繁的用浏览器登录了,会检测的。
3. 在你出问题的请求代码后面写入sleep几秒,这样就比较稳定
所以我调整过后的代码很稳定,每一次请求都会sleep一段时间,基本爬下来几百个用户不成问题,效果如下
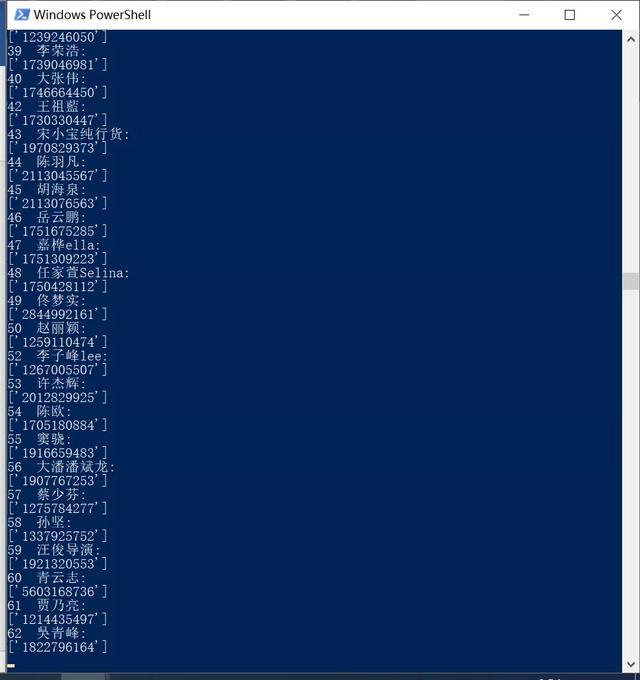
将爬取结果写入文件效果如下:

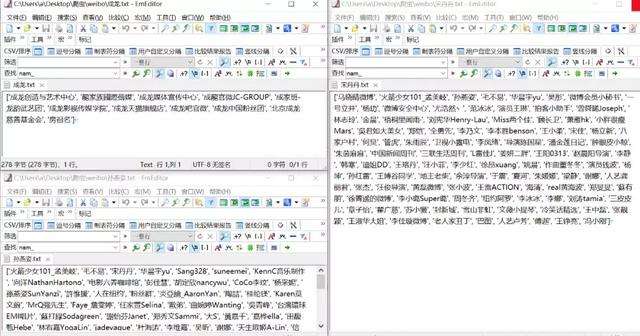
稳定递归+写入文件代码如下,完整代码已经放在github上
https://github.com/smityliu/spider/blob/master/weibo_login.py:
def follow_spider(id_all,turn): #控制迭代次数 if(turn == 2): print('\n'+"已经达到需要爬取的层数,准备退出......") exit() else: #最外层的for,是用来循环这一层函数中id_all的值 print('第'+str(turn)+'层开始:'+'\n'+'该层需要爬取的id有:') print(id_all) uid_all=[] for id in id_all: people=0 time.sleep(5) #登录以后使用新的headers headers_logined={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0'} #先标记名字id url_for_name='https://weibo.cn/'+id try: l=session.get(url=url_for_name,headers=headers_logined,timeout=3) name=re.findall(r'title>(.*?)的微博/title>',l.text) print('\n'+'开始爬取'+id+'||'+name[0]+'的所有关注\n') except: continue follow_url= 'https://weibo.cn/'+str(id)+'/follow' login=session.get(url=follow_url,headers=headers_logined,timeout=3) pages = re.findall(r'value="跳页" />1\/(.*?)页',login.text) #print(pages) if len(pages)==0: print('\n'+"只有一页,以下是"+id+'||'+name[0]+'的所有关注') page_all=['0'] else: page_all=str(pages[0]) follow_all=[] uid_part=[] print(page_all) if(page_all[0]=="0"): follow_url = 'https://weibo.cn/'+str(id)+'/follow' login=session.get(url=follow_url,headers=headers_logined,timeout=3) follow_part=re.findall(r'td valign="top">a.*?href="(.*?)">(.*?)/a>',login.text) follow_all = follow_all+follow_part else: #循环取每一页的关注和他的主页,但是这里取不到id,所以还得继续根据主页取 for page in range(int(page_all)): page = page+1 follow_url = 'https://weibo.cn/'+str(id)+'/follow?page=' + str(page) login=session.get(url=follow_url,headers=headers_logined,timeout=3) #匹配出来结果为关注的用户名昵称,是个二重数组,list里面再有一个list,follow_part[1][0]取主页url,follower[1][1]来取用户名 follow_part=re.findall(r'td valign="top">a.*?href="(.*?)">(.*?)/a>',login.text) follow_all = follow_all+follow_part time.sleep(3) #当关注数量大于150个的时候,跳过不计算 #follow_all为所有关注及其对应的主页 print(follow_all) #根据主页取每一个关注的id,凑成uid_all name_list=[] for s in range(len(follow_all)): if("微博" in follow_all[s][1]): continue follower=session.get(follow_all[s][0],headers=headers_logined,timeout=3) uid = re.findall(r'私信/a>a href="/(.*?)/info">资料/a>',follower.text) print(str(s) +' '+ follow_all[s][1] + ': ') print(uid) #这是某一个的总** uid_part = uid_part + uid name_list.append(follow_all[s][1]) #people=people+1 #if(people>50): # print("已经爬取前50个关注") # break time.sleep(1.5) print('\n'+'这是'+id+'__'+name[0]+'的所有关注') #写入每个文件的一定要是用户名,才好做数据对齐 print(name_list) file_name=name[0]+'.txt' with open('./weibo/'+file_name,'w',encoding="utf-8") as f: f.write(str(name_list)) #for one in uid_part: # url_one='https://weibo.cn/'+one # l=session.get(url=url_one,headers=headers_logined) # name_one=re.findall(r'title>(.*?)的微博/title>',l.text) # name_list = name_list+name_one print('\n该用户的关注名单已经写入文件\n') #这层的某一个算完以后加入这一层的总**) uid_all=uid_part+uid_all #print('第'+str(turn)+'层得到的结果:') #print(uid_all) #最外层循环结束 print('\n'+'第'+str(turn)+'层结束:') turn = turn +1 follow_spider(uid_all,turn)推特模拟登录
推特的模拟登录是这个项目里最难的,网络上的方法大多数都不行,都是好几年前的,推特早就不用那个结构了。
我们来分析一下推特,发现没有任何验证码,有点高兴:
但是我们直接截取登录报文,尝试登录却发现他有好多随机的字段,特别是这个authenticity_token,你直接复制一个现成的肯定是不行的,模拟登录后一定是跳转302到login界面,告诉你登录失败。而且他登录的url是sessions,并不是login.html,推特的前端验证做的还是挺精细的。

但是也有漏洞,我们发现直接访问
https://twitter.com/login
这个页面,直接就有authenticity_token
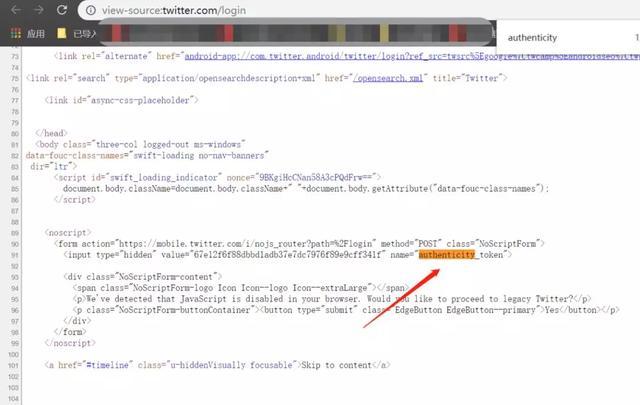
所以其实他只是一个访问前端就可以获取的随机值,因此我们的模拟登录如下:
完整代码在(https://github.com/smityliu/spider/blob/master/weibo_login.py)

还没有结束,推特的模拟登录成功不是重点,他难就难在,你想查看用户的信息,后台是调用各种api来返回给你json数据
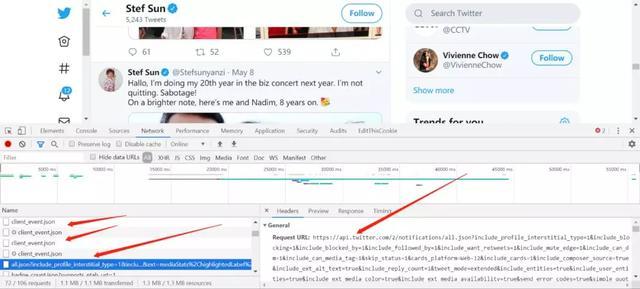
你登录了,肯定想:欸我直接爬
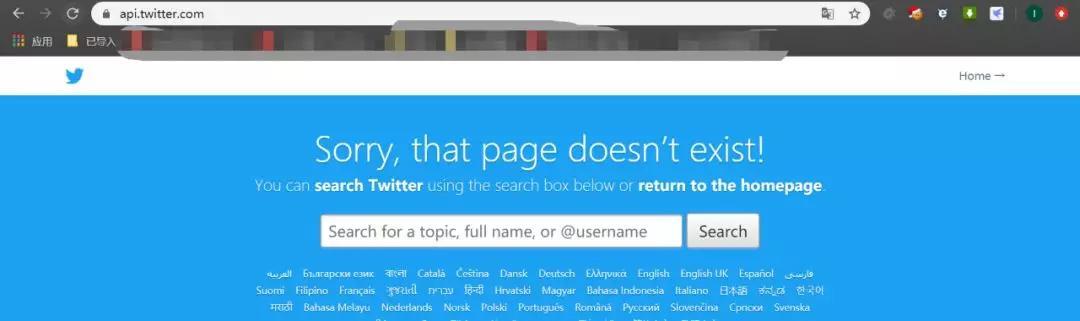
https://twitter.com/Stefsunyanzi/following
它不香么
不好意思,还真不行,你直接爬取following页面,里面会调用各种api接口,你只爬下来了一个following页面都是代码,一找api,都是404,直接爬会出现这个页面
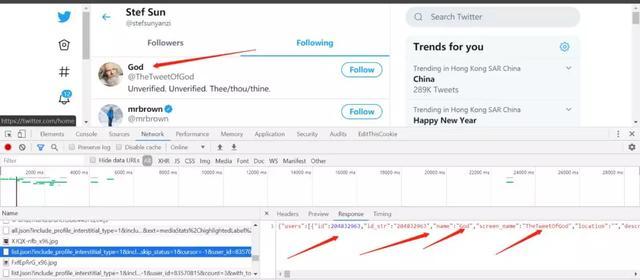
我们攻破这个api,真的是一个很麻烦,很繁琐的过程,一堆json让你看,你得一个个响应包看过去,终于看到了关注人员的json包:
如果你想侥幸,直接复制当前的所有header和data进行requests请求,那么它一定返回:
{"errors":[{"code":215,"message":"BadAuthentication data."}]}
因为你的请求方式不对。
我们看一下它的请求包:
Request URL: https://api.twitter.com/1.1/friends/list.json?include_profile_interstitial_type=1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36x-csrf-token: 081e09c5b2c1b13627ee8a9309de6131x-twitter-active-user: yesx-twitter-auth-type: OAuth2Sessionx-twitter-client-language: eninclude_profile_interstitial_type: 1include_blocking: 1include_blocked_by: 1include_followed_by: 1include_want_retweets: 1include_mute_edge: 1include_can_dm: 1include_can_media_tag: 1skip_status: 1cursor: -1user_id: 83570815count: 20这看一下傻眼了,好消息坏消息一起来:
你说这个好登录吧,它也很好登录,因为authorization(我自己的删除了)这个东西就是储存你登录信息的字段,你只要有了这个字段,随便调用api了。
你说这个难登录吧,它贼难,各种随机字段,x-csrf-token这个字段真的是很劝退了,你如果你忽略这个字段,它一定提示你,this requests need matchcsrf-token这个报错,就是告诉你你得有这个token,我们曾经为了这个问题,真的几乎快放弃了推特登录。
但是真的上天眷顾不放弃的人,偶然一天晚上随便看字段发现个不得了的东西:
cookie: _ga=******; tfw_exp=0; kdt=w******; remember_checked_on=1; csrf_same_site_set=1; csrf_same_site=1; des_opt_in=Y; fontsLoaded=true; ct0=081e09c5b2c1b13627ee8a9309de6131; _gid=******; lang=en; _sl=1; personalization_id="v******"; guest_id=******; ads_prefs="HBERAAA="; _twitter_sess=******; auth_token=******; rweb_optin=side_no_out; twid=u%3D1203136912770224128; _gat=1这cookie里的ct0字段不就是我们要找的x-csrf-token吗,但是还有一个问题就是,这个东西到底是服务端给的,还是自己客户端随机生成的,我们实验了一下:
每次的x-csrf-token都不一样,但是长度肯定是一样的
直接修改x-csrf-token为97e791a574a3a81468622aefcee61068,然后请求,他返回的结果写入文件后就是:
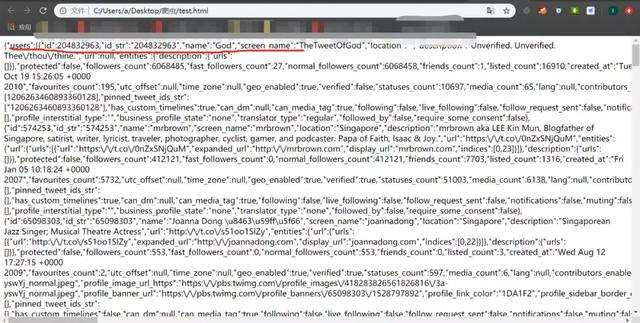
请求返回的是我们需要的json内容,而不是405请求失败,里面包含了用户的id,用户的昵称和用户的唯一名字。
这个说明csrf-token在推特的登录机制中是由客户端生成并且给服务端的,这个就很好做了啊,我随便使用一个曾经登录获取到的csrftoken然后修改cookie里的ct0字段为这个值,就可以直接登录了。
怎么看用户的id呢,
观察提取用户关注的url,发现是和用户id有关的:
https://api.twitter.com/1.1/friends/list.json?include_profile_interstitial_type=1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36', #建议每次用脚本之前,都去浏览器再重新更新一下cookie,以防过期,获取过程很简单,直接看发包就可以了,然后整个脱下来。 'Cookie':'_ga= , 'x-csrf-token':'97e791a574a3a81468622aefcee61068'} position=0 id_next_all=[] follower_name_all=[] for ids in id_all: url='https://api.twitter.com/1.1/friends/list.json?include_profile_interstitial_type=1','_').replace('>','_').replace('|','_').replace('\'','_') filename=str(name_all[position])+'.txt' print(filename) print('\n') try: with open('./twitter/'+filename,'w',encoding='utf-8') as f: f.write(str(follower_name)) except: pass position=position+1 id_next_all=id_next_all+id_next follower_name_all = follower_name_all + follower_name turn = turn +1 print(id_next_all) print(follower_name_all) spider_follower(id_next_all,follower_name_all,turn)
完整代码在
https://github.com/smityliu/spider/blob/master/twitter_login_test.py
各位使用的时候只要截取一下流量包,输入你的用户名密码,和authorization,cookie,然后将cookie里的ct0字段填入csrftoken(可以循环利用,不检查),就可以愉快的一直爬取了。实在用不来可以联系我。
效果如图:
左边是推特,右边是微博
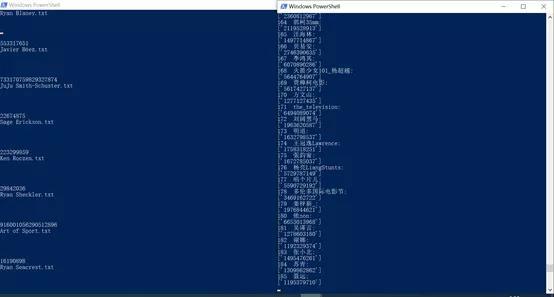
写入文件后

有趣的是我这里发现authorization其实是来自登录后的主页js文件

如果你们有兴趣可以再把爬虫智能化一点。合天网安实验室的一个相关实验:通过该实验,基于之前所学的爬虫知识,了解一些常用的百度的高级搜索语法,并且自己编写一个属于自己的url采集器。复制链接做实验啦:http://www.hetianlab.com/expc.do?ec=ECID2a0a-fa3e-461c-a570-8fe95bbedd46
下一篇预告
我们拿到了所有的数据,将开始我们的收尾工作:
1. 做数据对齐,两个网络如何保证你能够确定融合数据得两个用户是同一个人,必须得找到相关得信息。我们采取的是对比关注人物的相似度,但是第一个问题在于,国内明星在推特上大部分都是英文名,所以还得做一步工作,就是百度引擎搜索推特关注的英文名,并且提取第一页词条出现频率最高的词语作为这个用户的中文代号,比如JJ_LIN,排除停用词后,百度词条首页最多出现的的是林俊杰,那么就将林俊杰替换推特里的JJ_LIN
2. 将微博的每一个用户的关注以用户名命名存放在weibo目录下,推特也类似,存放在twitter目录下,然后利用余弦定理相似度比较法,计算两个文件夹中每个分词后,两两比较得出的词语之间的距离,用距离关系来判断相似程度大小
3. 同时加上关注人员的社会属性,社会属性在第一篇爬虫里面就有提到,可以直接爬取到对应用户的微博里面的社会认证资料,那个是完全正确的
4. 最后,融合微博帖子和推特的推文,用第二篇LDA重新训练,得到兴趣属性
声明:笔者初衷用于分享与普及网络知识,若读者因此作出任何危害网络安全行为后果自负,与合天智汇及原作者无关!
转载请注明来自网盾网络安全培训,本文标题:《基于社交网络爬虫分析人物兴趣属性(三)》
标签:合天智汇
- 上一篇: 记一次授权的APK渗透测试
- 下一篇: 关于等保2.0,你到底有多了解?











