 freebuf
freebuf人工智能技术具有改变人类命运的巨大潜能,但同样存在巨大的安全风险。攻击者通过构造对抗样本,可以使人工智能系统输出攻击者想要的任意错误结果。从数学原理上来说,对抗攻击利用了人工智能算法模型的固有缺陷。本文以全连接神经网络为例来介绍对抗样本对人工智能模型作用的本质。
一、背景
近年来,随着海量数据的积累、计算能力的提高、机器学习方法与系统的持续创新与演进,人工智能技术取得了重大突破,成功应用于图像处理、自然语言处理、语音识别等多个领域。在图像分类、语音识别等模式识别任务中,机器学习的准确率甚至超越了人类。
人工智能技术具有改变人类命运的巨大潜能,但同样存在巨大的安全风险。这种安全风险存在的根本原因是机器学习算法设计之初普遍未考虑相关的安全威胁,使得机器学习算法的判断结果容易被恶意攻击者影响,导致AI系统判断失准。2013年,Szegedy等人首先在图像分类领域发现了一个非常有趣的“反直觉”现象:攻击者通过构造轻微扰动来干扰输入样本,可以使基于深度神经网络(DNN)的图片识别系统输出攻击者想要的任意错误结果。研究人员称这类具有攻击性的输入样本为对抗样本。随后越来越多的研究发现,除了DNN模型之外,对抗样本同样能成功地攻击强化学习模型、循环神经网络(RNN)模型等不同的机器学习模型,以及语音识别、图像识别、文本处理、恶意软件检测等不同的深度学习应用系统。
从数学原理上来说,对抗攻击利用了人工智能算法模型的固有缺陷,即人工智能算法学习得到的只是数据的统计特征或数据间的关联关系,而并未真正获取反映数据本质的特征或数据间的因果关系,并没有实现真正意义上的“智能”。本文以全连接神经网络为例来介绍对抗样本对人工智能模型作用的本质。
二、对抗样本简介
神经网络是目前人工智能系统中应用最广泛的一种模型,是一种典型的监督学习模型。尽管例如生成式对抗网络(Generative Adversarial Networks, GAN)等模型号称是无监督算法,但是其本质是将神经网络进行组合而来,模型中每个神经网络仍然是监督学习算法。对于最基本的神经网络来说,其训练过程如图1所示。
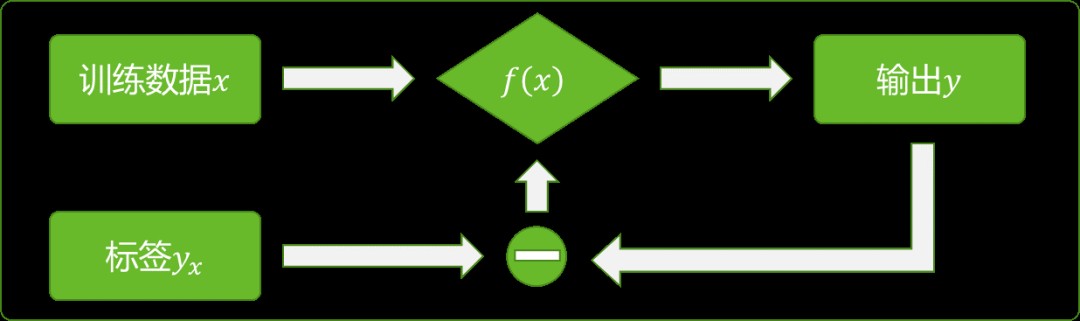
图1 神经网络训练过程
神经网络模型可以被看成是一个从数据集到标签集的映射,用y=f(x)表示,其中,x 为神经网络的输入数据,y为输出数据,yx为数据x对应的标签。在训练过程中,对于输入数据x,比较神经网络的输出y与标签yx,根据二者的差值来更新神经网络模型y=f(x)中的参数,即权重和偏置的值。训练好的模型即可以用来进行分类。对抗样本对模型y=f(x)的影响如图 2所示。
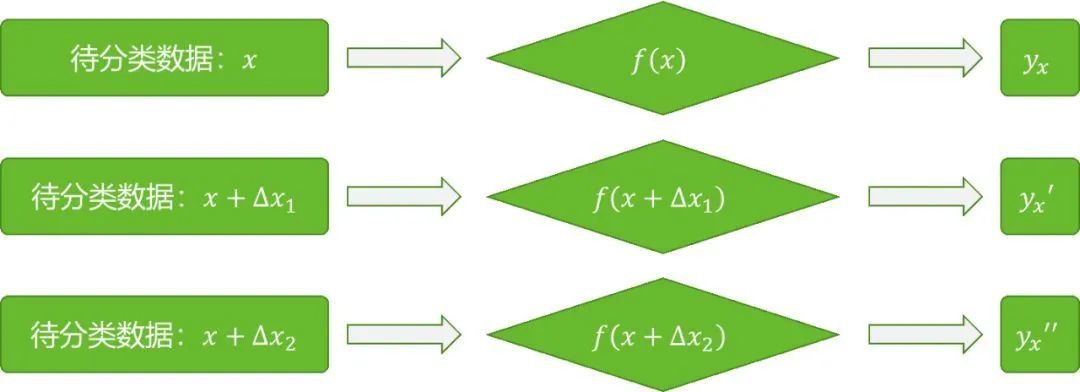
图2 对抗样本对神经网络模型的影响
对输入数据x中加入一个扰动量(图2中的∆x1和∆x2),可以使模型y=f(x)的输出发生较大的变化。通常,扰动量‖∆x1‖和‖∆x2‖都很小。例如在图像识别的应用中,只改变输入图像中的少部分像素,甚至只修改一个像素的值,就可能使分类器做出错误的判断。对于一个已经训练好的模型y=f(x)来说,并不是对所有的输入数据x进行扰动都可以使其输出发生较大的改变,同时,对于一个输入数据x,往往也需要加入特定类型的扰动才会使模型输出发生变化。也就是说对抗样本的生成需要具备一定的条件。那么对抗样本与模型的关系是什么呢?接下来通过具体的案例来说明。
三、案例分析
理想的二分类问题
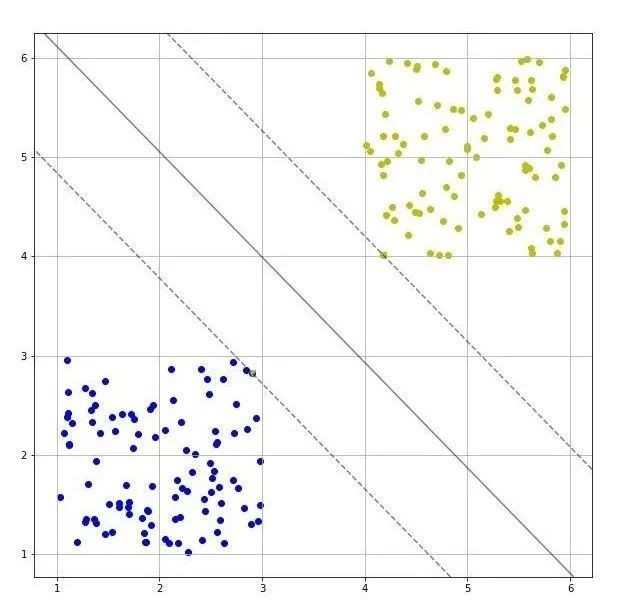
图3 理想的二分类问题
图3所示是一个线性二分类问题。两个类别之间差异度较大,因此可以较容易的找出两个类别的分类边界。而对于实际的问题来说,待分类数据的分布情况往往不可知。同时,实际问题的复杂性,噪声干扰等因素导致待分类数据集中不同类别数据之间的区分度并不明显。下面针对几种典型的数据集的二分类问题分别讨论。
线性二分类问题
考虑如图4所示的数据集。该数据集中的两个类别都是高斯分布。由于特征提取,数据噪声等原因,与图3中的数据集相比,该数据集中两类数据的距离较近,且有部分数据互相交叉,也就是说两类数据的区分度不明显。对该数据集采用神经网络模型进行分类,其模型的等高线图如图5所示。
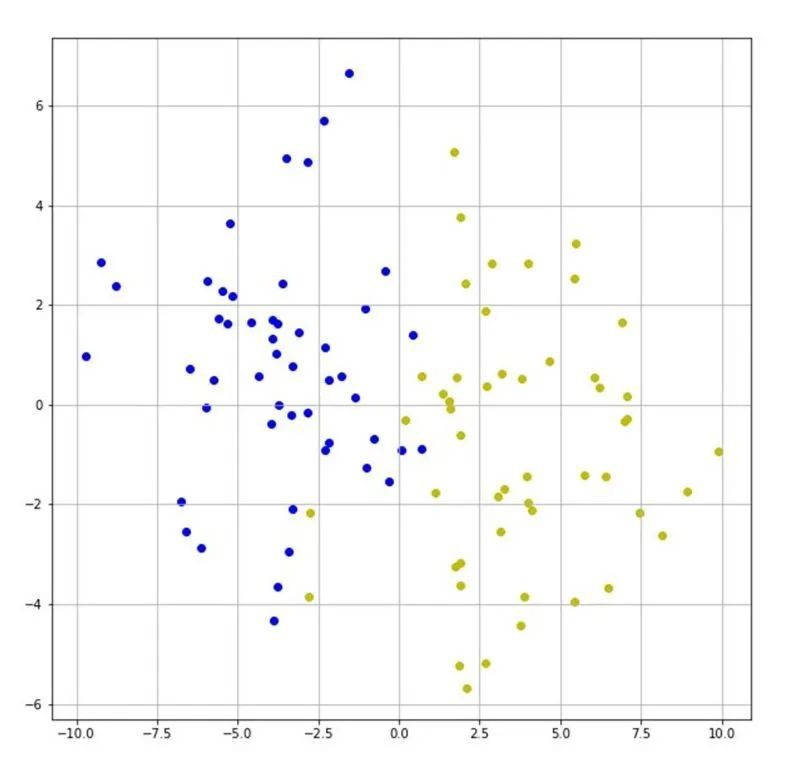
图4 线性分类数据集
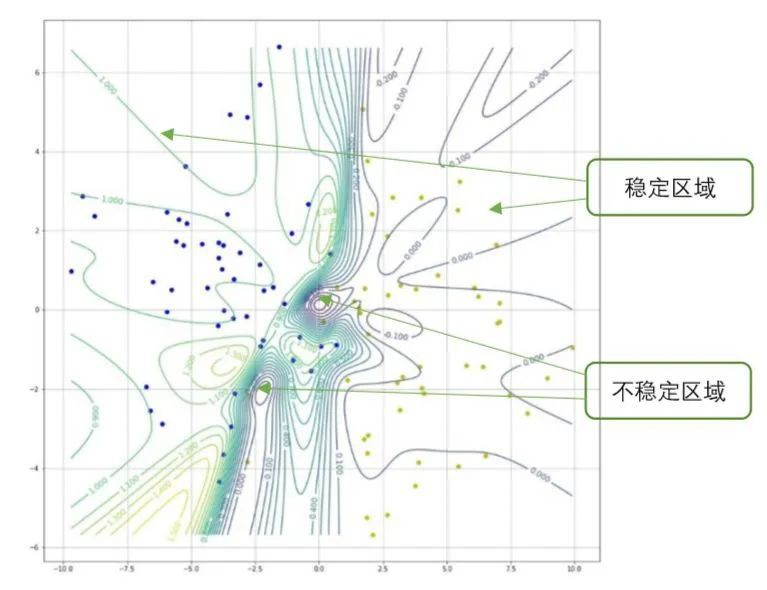
图5 线性分类的等高线图
在图5中,线条表示神经网络模型y=f(x)的等高线。根据等高线的密集程度,可以将二维平面分为不稳定区域和稳定区域。
不稳定区域:等高线密集的区域。在不稳定区域中,y=f(x)的梯度的绝对值较大,即函数值y随着x变化较快,x的微小变化会对y的值造成大的影响。
稳定区域:等高线稀疏的区域。在稳定区域中,函数值y随着x变化较慢,x的微小变化不会对y的值造成大的影响。
如图 5所示,如果输入数据落在神经网络模型的不稳定区域中,那么该模型在这个输入数据处容易被对抗样本欺骗。如果输入数据落在神经网络模型的稳定区域中,那么该模型在这个输入数据处就不容易被对抗样本欺骗。这就解释了在实际的神经网络模型中,例如图像识别的神经网络,某些输入图像经过微小的改动就能够使模型分类错误,而另一些图像即使经过较大的改动仍然可以使模型输出正确的分类结果。
另外,由梯度的定义可知,梯度向量与等高线是正交的。沿着梯度的方向函数值变化最快,而沿着等高线的方向,函数值不发生变化。因此对于落在不稳定区域的输入数据x来说,其对扰动∆x的敏感程度取决∆x与梯度向量(或等高线)的夹角。若∆x沿着梯度方向,那么微小的‖∆x‖就会使模型函数的输出y发生大的变化。如果∆x沿着等高线方向,那么即使‖∆x‖较大,函数的输出y也不会发生变化。这就解释了在实际的神经网络模型中,例如用于图像识别的神经网络,一些图像只有经过特定的扰动才会引起分类错误,而并不是针对图像的任何扰动都会引起分类错误。
双半月数据集的二分类问题
前面通过等高线分布图说明了对抗样本的作用机理。下面针对更加复杂的数据集来进一步展示。本节对双半月形数据集进行二分类。数据集和神经网络的等高线图分别如图6和图7所示。
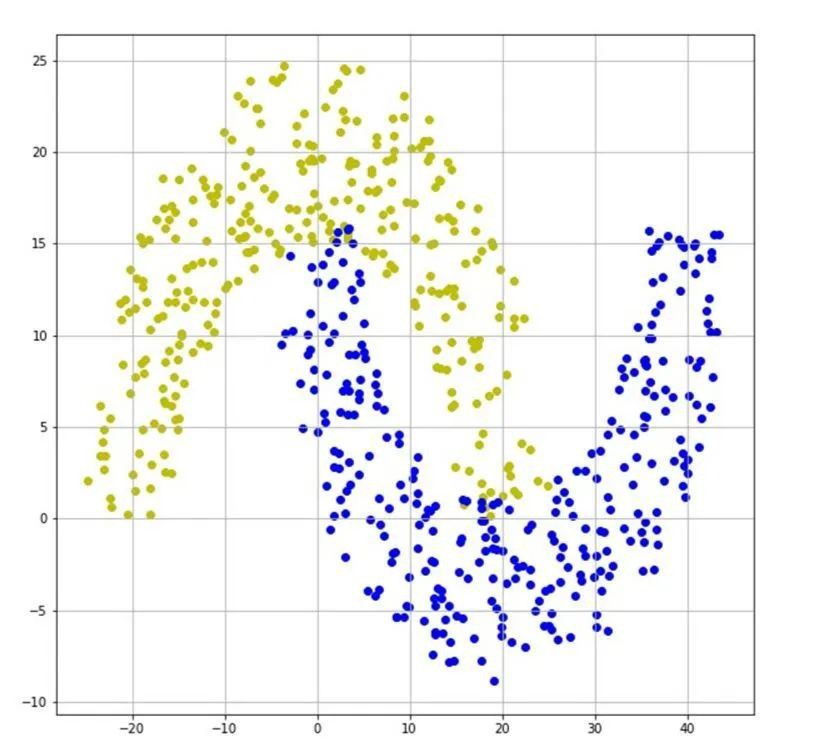
图 6 双半月形数据集
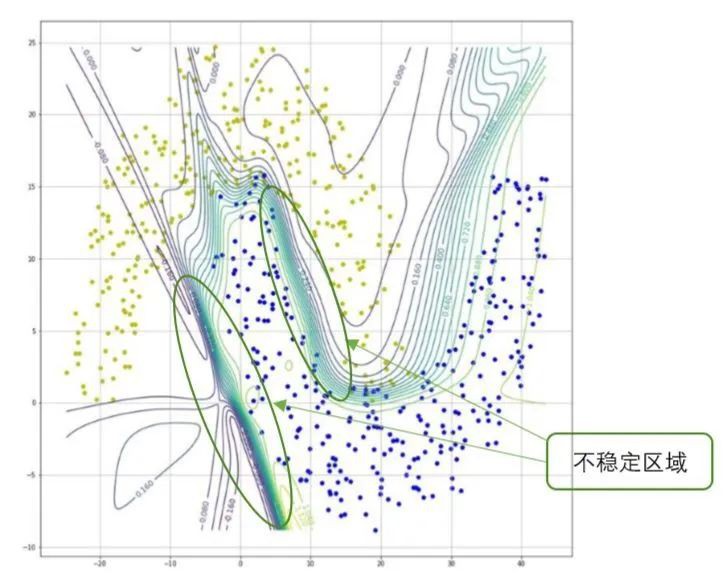
图7 双半月形数据集的等高线图
对于双半月形数据集,其分类模型函数的等高线分布更加复杂。在图6可以看出,两类数据之间的距离较近,同时还有部分交叉,因此决策边界处的等高线较密集。与线性分类相似,在等高线密集的区域,如果输入量x沿着梯度的方向发生微小的变动,那么就会导致模型的输出y发生较大的变化。
环形数据集
环形数据集和其神经网络的等高线图分别如图8和图9所示。
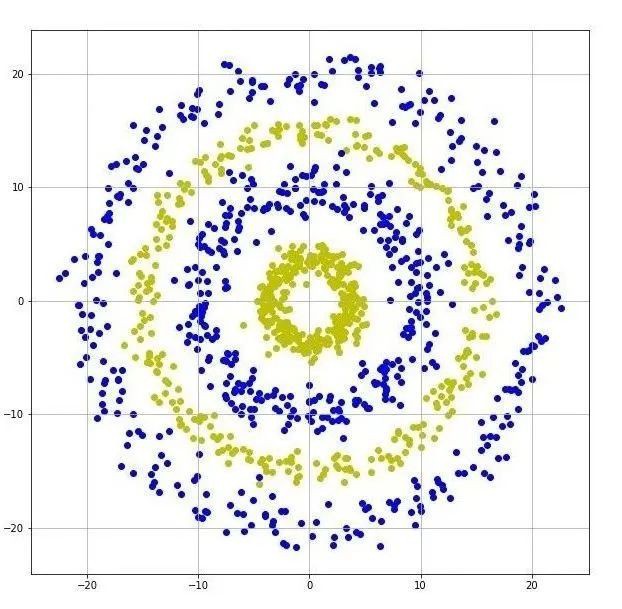
图8 环形数据集
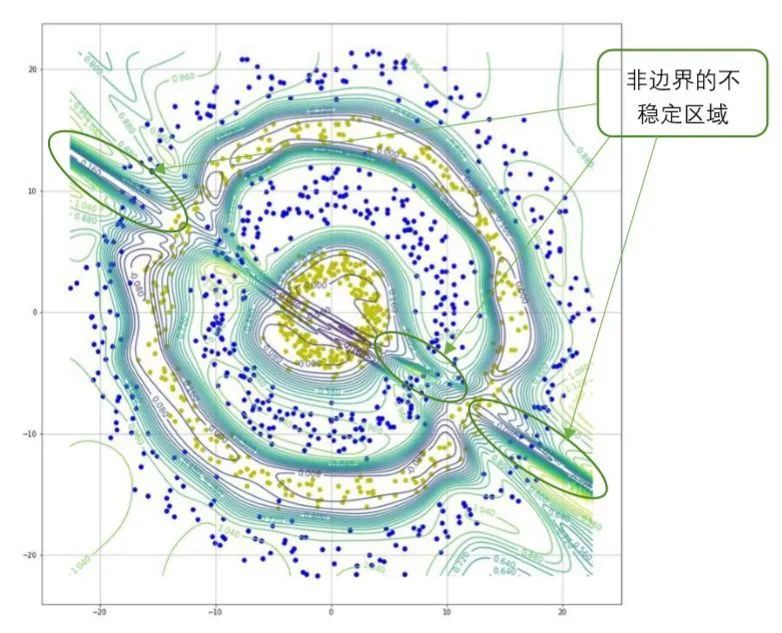
图9 环形数据集的等高线图
图8所示的数据集中的两类数据同样距离较近,且有部分交叉。从图9可以看出,等高线更加复杂,不稳定区域也更多。由于两类数据的距离较近,因此决策边界处属于不稳定区域。同时,在非边界处也出现了等高线密集的区域。也就是说在非决策边界处也出现了不稳定区域,如图9中所示。在这些不稳定区域中,模型容易被对抗样本所欺骗。可见,对于复杂分布的数据集来说,模型的不稳定区域更多,分布也更加复杂。
四、总结
以上通过不同的数据集展示了神经网络模型被对抗样本欺骗的原理。为了方便说明,以上数据集中的数据都为二维,可以直观的通过图像来展示。随着数据集中的数据分布越来越复杂,模型的不稳定区域会更多,同时不稳定区域的位置也更加难以预测。在实际应用中,数据集的维度往往非常高,例如MNIST数据集每个样本有784个特征,即784维;CIFAR数据集每个样本有3072个特征,即3072维。对于高维的数据空间,其数据的分布往往不可知,且模型的决策边界更加复杂,无法通过图像来直观的展示,因此无法准确地知道模型不稳定区域的分布。目前学术界虽然提出了一些对抗攻击的防护方法,但效果都有限,其主要原因就在于目前已有的研究主要是通过各种方法改变了不稳定区域的位置,但并没有将其消除。对于高维数据集和更加复杂的分类模型来说,其模型的不稳定区域的分布不可预知。因此,对抗样本的防护问题现在并没有从根本上被解决,还需要从数学原理上进行更加深入的研究。
转载请注明来自网盾网络安全培训,本文标题:《专治各种不明白,一文带你了解“对抗样本原理”》
标签:对抗样本
- 上一篇: 细说php反序列化字符TAOYI
- 下一篇: 网络安全管理职业技能竞赛Web writeup











