freebuf
freebuf做信息安全的都免不了和计算机打交道,计算机是信息安全的主要防护对象之一,信息安全的工具也是在计算机上进行操作和使用,所以对计算机基础的了解有助于分析安全。计算机经过几十年的发展取得了长久的进步,速度越来越快,功能越来越强,形态差异越来越大。但现代计算机到底有多快,估计大多数人都没有直观概念,本文从计算机中的核心组件来分析下计算机到底有多快。
好在计算机的原理这么多年都没有怎么发生过本质的变化,从结构上看,还是cpu,缓存,内存,硬盘,网络等主要内容,下面就逐步分析和介绍这些内容的速度到底是多少。
一、时间概念
首先介绍几个时间概念:
纳秒(ns,十亿分之一秒)
微秒(μs,百万分之一秒)
毫秒(ms,千分之一秒)
秒(s)
差不多1s 是人类能感知的最小时间单位
二、数学知识:浮点数
然后再介绍一下数学知识中的浮点数:
什么是浮点数?浮点数表示的是一个数字,其小数点所在的位置是不确定的,也就是浮动的,因此称之为浮点数,浮点数分为单精度浮点数和双精度浮点数。
单精度浮点数(float):占用4个字节(32位)存储空间,包括符号位1位,阶码8位,尾数23位。其数值范围为-3.4E38~3.4E38。
双精度浮点数(double):占用8个字节(64 位)存储空间。其数值范围为:-1.79E+308~+1.79E+308。
三、CPU的速度
对计算机中的指令周期、CPU周期和时钟周期做下说明:
指令周期:是指计算机从取指令到指令执行完毕的时间
CPU周期:也称机器周期,把一条指令的执行过程划分为若干个阶段,每一阶段完成一项基本操作,完成一个基本操作所需要的时间称为CPU周期,通常用内存中读取一个指令字的最短时间来规定CPU周期。
时钟周期:也称为振荡周期,定义为时钟频率的倒数。时钟周期是计算机中最基本的、最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作。
下面就了解下CPU到底有多快,在频率为3.0GHz的cpu中,也就是说每秒可以执行3*10^9个指令。大部分简单指令的执行只需要一个时钟周期,也就是1/3纳秒左右。即使是真空中传播的光,在这段时间内也只能走10厘米(约4英寸)。
 在计算机中常用FLOPS来表示CPU的处理速度,FLOPS字尾的那个S,代表秒。
在计算机中常用FLOPS来表示CPU的处理速度,FLOPS字尾的那个S,代表秒。
FLOPS(即“每秒浮点运算次数”,“每秒峰值速度”)是“每秒所执行的浮点运算次数”是(floating-point operations per second)的缩写。
常用FLOPS单位:
MFLOPS(megaFLOPS):每秒一佰万(=10^6)次的浮点运算,
GFLOPS(gigaFLOPS):每秒十亿(=10^9)次的浮点运算,
TFLOPS(teraFLOPS):每秒万亿(=10^12)次的浮点运算,
PFLOPS(petaFLOPS):每秒千万亿(=10^15)次的浮点运算,
EFLOPS(exaFLOPS):每秒百亿亿(=10^18)次的浮点运算
ZFLOPS(zettaFLOPS):每秒十万京(=10^21)次的浮点运算。
CPU峰值性能:就是CPU运算能力满打满算最最理想情况下的性能。
CPU峰值性能计算公式:
峰值浮点性能=CPU核数×CPU频率×每周期执行的浮点操作数
每周期执行的浮点操作数:分单精度(SP)浮点性能和双精度(DP)浮点性能。这两个指标主要和CPU架构有关系:
例如:Intel Core 2 and Nehalem (SSE/SSE2):
4 DP FLOPs/cycle: 2-wide SSE2 addition + 2-wide SSE2 multiplication8 SP FLOPs/cycle: 4-wide SSE addition + 4-wide SSE multiplicationIntel Sandy Bridge/Ivy Bridge (AVX1):8 DP FLOPs/cycle: 4-wide AVX addition + 4-wide AVX multiplication16 SP FLOPs/cycle: 8-wide AVX addition + 8-wide AVX multiplicationIntel Haswell/Broadwell/Skylake/Kaby Lake/Coffee/... (AVX+FMA3)16 DP FLOPs/cycle: two 4-wide FMA (fused multiply-add) instructions32 SP FLOPs/cycle: two 8-wide FMA (fused multiply-add) instructions
比如CPU:E5-2690 v2,基本频率为3.0GHz(这里不考虑Turbo boost动态升频),有10个核,每个核每周期可以做8次双精度浮点运算或16次单精度浮点运算,因此:
单精度峰值浮点性能=3.0*10*16=480 GFLOPS
双精度峰值浮点性能=3.0*10*8=240 GFLOPS
可以理解此款CPU的单精度浮点运算峰值为480GFLOPS,双精度为240GFLOPS。
举个最新的AMD的3990x CPU为例,单精度浮点性能达到了8098GFLOPS(8万亿FLOPS),双精度浮点性能则为4016 GFLOPS(4万亿FLOPS)。
什么概念呢,1993年全部Top 500的超级计算机算力总和,也就1.1TFLOPS,也就是说AMD的3990x CPU的算力比当时世界上所有超级计算机算力的总和还多。
 2000年11月,国际TOP500组织宣布,当前最快的超级计算机的运算速度达到4938GFLOPS(4.9万亿FLOPS),应用了8000多个CPU。也就是说AMD的3990x CPU的算力,比2000年世界上最快的超级计算机的算力高出近1倍。
2000年11月,国际TOP500组织宣布,当前最快的超级计算机的运算速度达到4938GFLOPS(4.9万亿FLOPS),应用了8000多个CPU。也就是说AMD的3990x CPU的算力,比2000年世界上最快的超级计算机的算力高出近1倍。
2020年11月,数据依旧来源于国际TOP500组织,日本富士通公司的超级计算机的运算速度已经达到442,010TFLOPS,也就是说,相比2000年的4938GFLOPS,运算速度提高了约9万倍。
四、缓存
由于CPU的速度实在太快了,快到主存跟不上,在读取主存数据的时候CPU常常需要等待,浪费资源,所以在CPU内部集成了缓存来作为缓冲区域,就是为了缓解CPU和内存之间速度不匹配问题(结构:CPU→cache→memory)
缓存是当CPU进行读取数据的时候:
是先从缓存的数据进行查找的,读取之后再输入到CPU的寄存器里面进行处理的;
如果没有对应的缓存数据给CPU进行处理的话,那电脑就会从内存中拿数据给交给CPU进行 处理,但读取内存比读缓存数据要慢的多。
CPU处理完数据之后,就会把处理完的的数据模块进行保存,这个也是缓存数据,这些数据在以后进行读取操作的时候就会快很多,不会像以前那么慢,并且不会重复读取内存中的数据。
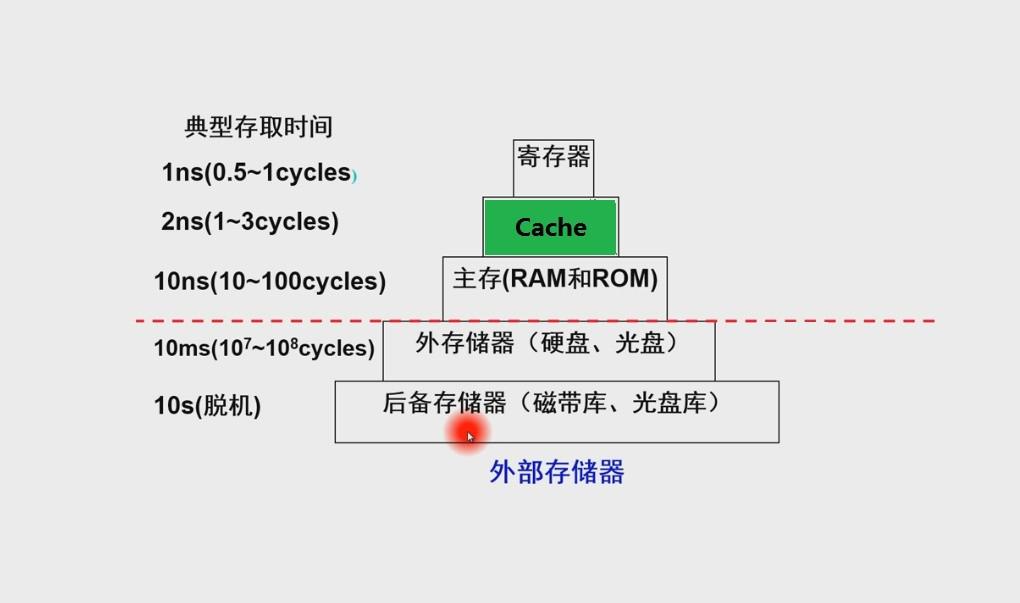 一级缓存读取时间为0.5ns,大约一次或者两次心跳的时间。这里能看出缓存的重要性,因为它的速度可以赶上 CPU,所以在CPU指令层级上的优化,提高缓存访问的命中率,这样可以极大的提高效率。但如果是命中预测错误则需要耗时 5ns,这个时间就慢了不少,所以你会看到很多文章分析如何优化代码来提高预测的概率,这样对运行效率可以提高不少。
一级缓存读取时间为0.5ns,大约一次或者两次心跳的时间。这里能看出缓存的重要性,因为它的速度可以赶上 CPU,所以在CPU指令层级上的优化,提高缓存访问的命中率,这样可以极大的提高效率。但如果是命中预测错误则需要耗时 5ns,这个时间就慢了不少,所以你会看到很多文章分析如何优化代码来提高预测的概率,这样对运行效率可以提高不少。
二级缓存时间就比较久了,大约在 7ns,可以看到的是如果一级缓存没有命中,然后去二级缓存读取数据,时间差了一个数量级。然后是三级缓存。

顺便提一下线程的互斥锁的加锁和解锁时间需要 25ns,首次会需要更长的时间。所以在并发编程中,我们经常听说锁是一个很耗时的东西就是这个原因。
五、内存
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都 是在内存中进行的,因此内存的性能对计算机的影响非常大。内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
但CPU读内存数据,每次内存寻址需要 100ns,相比缓存慢了很多,CPU 和内存之间的速度瓶颈被称为冯诺依曼瓶颈。
从内存中读取 1MB 的连续数据,耗时大约为 250us。
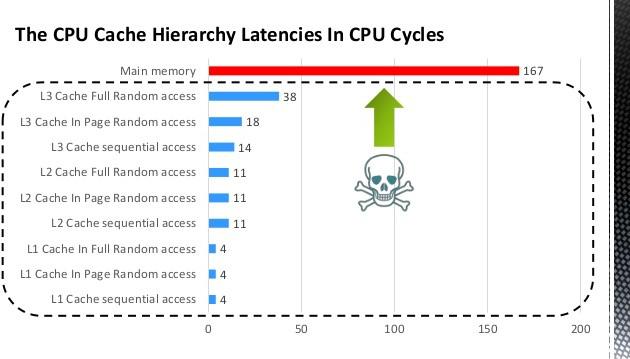 顺便提一下,一次CPU上下文切换(系统调用)需要大约 1500ns,也就是 1.5us,所以上下文切换是很耗时的行为。上下文切换更恐怖的事情在于,这段时间里 CPU 没有做任何有用的计算,只是切换了两个不同进程的寄存器和内存状态;而且这个过程还破坏了缓存,让后续的计算更加耗时。
顺便提一下,一次CPU上下文切换(系统调用)需要大约 1500ns,也就是 1.5us,所以上下文切换是很耗时的行为。上下文切换更恐怖的事情在于,这段时间里 CPU 没有做任何有用的计算,只是切换了两个不同进程的寄存器和内存状态;而且这个过程还破坏了缓存,让后续的计算更加耗时。
六、硬盘
硬盘的主要作用就是用来储存我们平时安装的软件、电影、游戏、音乐等的一个数据容器。现在的硬盘主要有ssd和普通机械硬盘。
SSD 随机读取耗时为 150us,虽然我们知道 SSD 要比机械硬盘快很多,但是这个速度对于CPU 来说也是像乌龟一样。I/O 设备 从硬盘开始速度开始变得漫长,这个时候我们就想起内存的好处了。尽量减少 IO 设备的读写,把最常用的数据放到内存中作为缓存是所有程序的通识。像 memcached 和 redis 这样的高速缓存系统近几年的异军突起,就是解决了这里的问题。
从 SSD 读取 1MB 的顺序数据,大约需要 1ms,也就是说 SSD 读一个普通的文件,如果要等你做完,CPU浪费了很多时间,但SSD 已经很快啦,不信你看下面机械磁盘的表现。
磁盘寻址时间为 10ms。机械硬盘使用 RPM(Revolutions Per Minute/每分钟转速) 来评估磁盘的性能:RPM 越大,平均寻址时间更短,磁盘性能越好。寻址只是把磁头移动到正确的磁道上,然后才能读取指定扇区的内容。换句话说,寻址虽然很浪费时间,但其实它并没有办任何的正事(读取磁盘内容)。
从磁盘读取 1MB 连续数据需要 20ms,IO 设备是计算机系统的瓶颈,希望读到这里你能更深切地理解这句话!如果还不理解,不妨想想你在网上买的东西,快递送了将近两年,你的心情是怎么样的。
七、网络
现在的网络无处不在,不管是有线还是无线网络现在都取得了长足的进步,但网络传输对CPU 来说还是太慢了。
在 1Gbps 的网络上传输 2K 的数据需要 20us,可以看到网络上非常少数据传输对于 CPU 来说,已经很漫长。而且这里的时间还是理论最大值,实际过程还要更慢一些。

同一个数据中心网络上跑一个来回需要 0.5ms。如果你的程序有段代码需要和数据中心的其他服务器交互,在这段时间里 CPU 都已经休息了很长时间。减少不同服务组件的网络请求, 是性能优化的一大课题。
而从世界上不同城市网络上走一个来回,平均需要 150ms(参考世界各地 ping 报文的时间),不难理解,所有的程序和架构都会尽量避免不同城市甚至是跨国家的网络访问,CDN就是这个问题的一个解决方案:让用户和最接近自己的服务器交互,从而减少网络上报文的传输时间。
前面介绍了计算机中的各个组件相对于CPU的时间,虽然很多组件相对于CPU来说还是很慢,但考虑到人对时间感官是秒为单位的。所有现代的计算机对人类来说还是太快了。不过了解这些内容会加深对计算机的理解,对软件开发优化可起到一定的帮助。
备注:以上数据来源于网络,没有经过实际测试和验证,如果有错误欢迎批评指正。
转载请注明来自网盾网络安全培训,本文标题:《计算机超速进化,你准备好了吗?》