freebuf
freebuf最近的CVE-2022-0185还是挺有意思的,在谷歌kctf(基于 K8s 的 CTF)中被发现。这个洞是在Linux内核的文件系统上下文中功能中的legacy_parse_param函数验证长度的代码处有缺陷,导致了一个基于堆的缓冲区溢出(整数下溢)。
攻击影响为越界写入/拒绝服务/权限提升和特定场景下的容器逃逸(k8s)。
其中会涉及到一些容器安全的基础小知识,有必要简单学习一下这个洞。
0x01 前置知识
1.Capabilities机制
这个机制在容器逃逸中很常见
suid和capabilities
capabilities机制是一种在Linux权限控制机制中的一种,这里权限控制是指对root的权限进行划分控制。
首先要知道suid(Set owner User ID)对于权限的控制,suid的含义是允许一个文件的owner在执行这个文件的时候,以root的权限执行,不需要密码。比如普通用户改密码使用的passwd命令(euid会设置为这个程序的所有者,root的话euid会设置为0)。而suid是有安全隐患的,简单来说就是有的情况下suid设置后去运行一个命令时,只是需要一小部分特权但是suid却给了root的全部权限,常见渗透中的的suid提权就是因为一个程序的所有者是root或者高权用户,并且有suid权限,才会可以被利用来提权。
suid控制权限太粗糙,所以引入的capabilities机制(Linux内核2.2后引入),和suid直接以root高权来运行程序不同的是,capabilities机制将root权限进行细分,可以对细分后的“子权限”来进行启用或者禁用。比如进行实际操作的时候,euid不为root的话,便会检查是否具有该特权操作所对应的capabilities,来决定是否可以执行特权操作。
常见特权操作对应的capabilities如下:
更多capabilites 列表详细见:http://man7.org/linux/man-pages/man7/capabilities.7.html
Capabilities集合分类
Capabilities的类型可以分为线程/进程的Capabilities和文件的Capabilities两种,并且capabilities在进程与文件中的集合分类稍有区别。分别集合的含义都简单的标注了一下,了解即可。
文件中的Capabilities有三个集合:
- Permitted #集合的上限,权限不过超过这个集合
- Inheritable #通过execve继承给新进程的能力
- Effective #一个标识位,是否开启影响执行execve() 后,线程 Permitted 集合中的 capabilities 是否会自动添加到它的 Effective 集合中
进程中的Capabilities有五个集合:
- Permitted #集合的上限,权限不过超过这个集合
- Inheritable #通过execve继承给新进程的能力
- Effective #标志位,内核正在检查是否可以特权操作就是检查这里。
- Bounding
- Ambient
上面的两个集合只标注了比较重要的部分,而这俩类型的集合会确定最终程序运行起来的capabilities,是有标准的计算公式的。篇幅原因这里不展开叙述。
获取和设置capabilities
常见使用libcap来管理Capabilities。
获取capabilities也很简单,比如可以通过/proc//task//status文件来查看线程的capabilities:
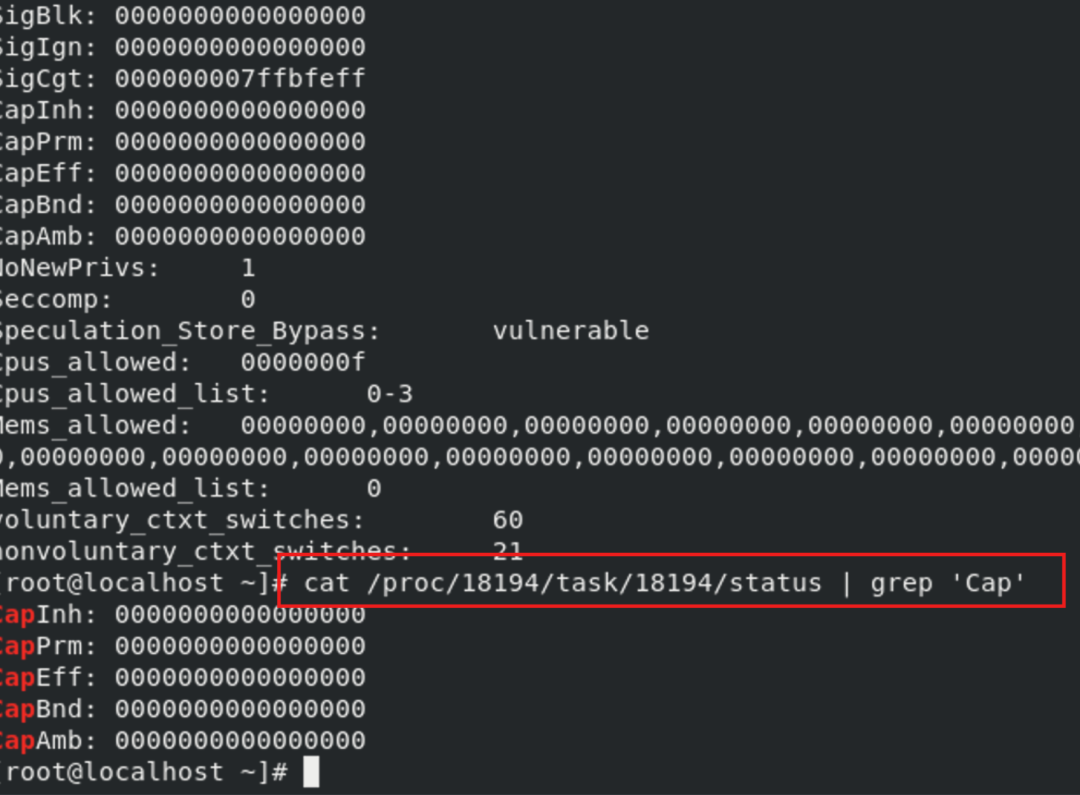
得到一堆数值没办法知其意,可以使用capsh进行转换。
capsh --decode=0000003fffffffff

上面查看的数值后转换也并不方便,libcap提供了getcap和setcap两个命令来分别查看和设置文件的capabilities,方便查看对应的capabilities:
getcap /bin/ping

即该文件的capabilities中,Permitted集合中包含了CAP_NEW_RAW,从而可以发送raw packet。这也就应找了避免权限滥用,ping程序只需要网络相关的特权即可,所以这里有cap_net_raw即可普通用户运行。
CAP_SYS_ADMIN
CVE-2022-0185中涉及使用到了CAP_SYS_ADMIN这个capabilities,它提供众多命令的权限,mount、unmout、swapon等等。
而在docker或其他容器化环境提供的标准创建中一般不会有加上CAP_SYS_ADMIN这个功能,也就说如果要有CAP_SYS_ADMIN能力就必须在创建的时候有加CAP_SYS_ADMIN参数或者使用特权容器--privileged标志,而CAP_SYS_ADMIN可以通过unshare进行系统调用获得这个能力,unshare系统调用会将进程分配至新的namespace,比如unshared -U会使用户进入新的用户命名空间,又因为Linux capability继承的机制,新的namespace拥有全部的capabilities,也包含了CAP_SYS_ADMIN。
2.seccomp过滤器
Seccomp 全称Secure computing mode,意为安全计算模式,自 2.6.12 版本以来一直是 Linux 内核的功能。它可以用来对进程的特权进行沙盒处理,从而限制了它可以从用户空间向内核进行的调用。
只有当Docker在构建时使用了Seccomp,并且内核在配置时启用了CONFIG_SECCOMP,这个功能才可用。可以用以下命令来检查当前环境是否支持Seccomp:

在CVE-2022-0185漏洞中非特权用户可以使用unshare进入新的命名空间来利用漏洞,而unshare命令会被docker 的seccomp过滤器阻止,该过滤器会阻止该命令使用的系统调用。
这里随便跑个docker看看,可以看到seccomp默认开启,无法使用unshare:
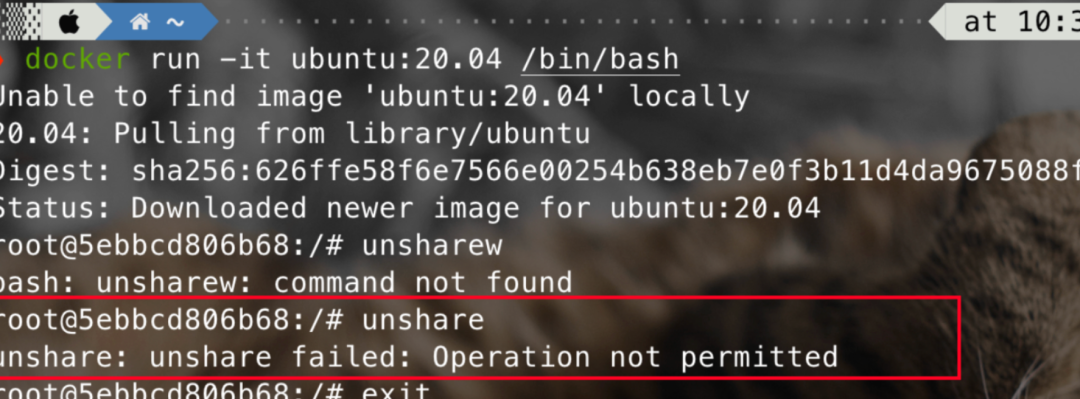
而在k8s集群中使用docker时,可以看到seccomp过滤器默认是被禁止的,可以使用unshare:
kubectl run -it yourname --image=ubuntu:20.04 /bin/bash
自1.22版本开始,Kubernetes引入了SeccompDefault特性来增强集群环境内的安全性。当该特性启用时,kubelet将默认使用由容器运行时定义的RuntimeDefault Seccomp配置文件,限制集群环境内的系统调用。
但当处于低版本(1.22版本之前)的Kubernetes集群环境中,在默认配置情况下,非特权用户可以在Pod内部顺利执行unshare系统调用。
整理一下漏洞成因的流程就是:
低于1.22的k8s环境默认给pod非特权用户执行unshare的系统调用-->拿到cap_sys_admin cap-->系统调用fsconfig处理文件系统上下文-->处理过程中代码存在整数下限溢出,可以绕过检查和越界写入。
检查内核是否受影响
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.nodeInfo.kernelVersion}{""}{end}' 3.namespace
看容器逃逸的洞和手法时候总会看到namespace和cgroup两个基础概念,namespace实现了资源的隔离,而cgroup实现了控制。
Linux命名空间是操作系统内核级别的资源隔离方案,每个进程只能访问自己所处命名空间的资源,因此每个容器才被做到被隔离的效果。拿docker运行来说,每当使用docker启动容器时,Docker在后台为容器创建了一组独立的命令空间,它拥有自己的主机名、进程空间、用户和网络,这使得一个运行在容器中的进程几乎看不到不到另一个容器或者宿主机中的进程。
最早的chroot命令大家都知道,通过修改根目录把用户隔离到一个特定目录下,chroot提供了一种简单的隔离模式,chroot内部的文件系统无法访问外部的内容。linux命名空间在这个基础上提供了对UTS、IPC、mount、PID、network、User等的隔离机制(https://lwn.net/Articles/531114/):
Mount: 隔离文件系统挂载点,类似 chroot,将一个进程放到一个特定的目录执行。
UTS: 隔离主机名和域名信息,使其在网络上可以被视作一个独立的节点而非 主机上的一个进程。
IPC: 隔离进程间通信,Linux 常见的进程间交互方法,包括信号量、消息队列和共享内存等。
PID: 隔离进程的ID,不同用户的进程就是通过 pid 命名空间隔离开的,且不同命名空间中可以有相同 pid。
Network: 隔离网络资源。网络隔离是通过 net 命名空间实现的,每个 net 命名空间有独立的 网络设备,IP 地址,路由表,/proc/net 目录。这样每个容器的网络就能隔离开来。(Docker 默认采用 veth 的方式,将容器中的虚拟网卡同 host 上的一 个Docker 网桥 docker0 连接在一起)
User: 隔离用户和用户组的ID,每个容器可以有不同的用户和组 id, 也就是说可以在容器内用容器内部的用户执行程序而非主机上的用户。
通过ls -l /proc/$pid/ns | awk '{print $1, $9, $10, $11}'可以看到对应进程所属的命名空间
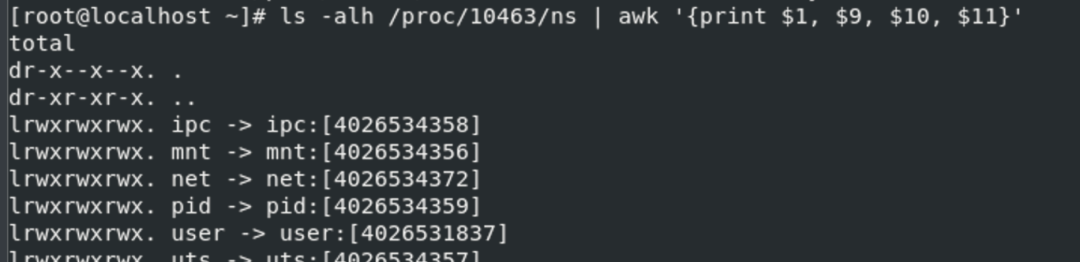
namespace 有三个系统调用可以使用:clone,unshare,setns
- clone() --- 实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述参数达到隔离。
- unshare() --- 使某个进程脱离某个 namespace
- setns(int fd, int nstype) --- 把某进程加入到某个 namespace
0x02 CVE-2022-0185漏洞成因
漏洞前提条件是需要CAP_SYS_ADMIN是因为漏洞发生的系统调用是fsconfig ,其中的 FSCONFIG_SET_STRING 操作选项会对已经打开的文件系统上下文进行一些配置,配置过程中的代码产生的漏洞。
fsconfig系统调用:
linux-5.11\fs\fsopen.c
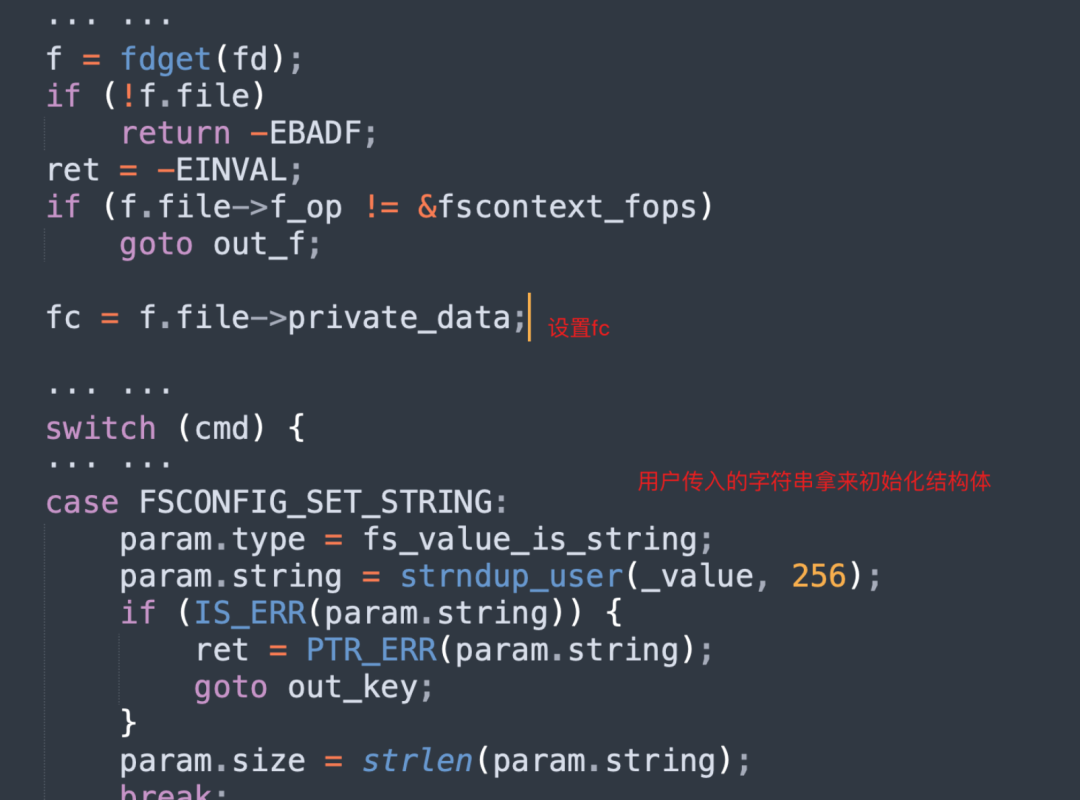
fsconfig系统调用入口中先根据文件描述符fd 初始化文件系统上下文结构体fc,然后根据用户传入的参数设置param结构体,进入vfs_fsconfig_locked函数:
linux-5.11\fs\fsopen.c:
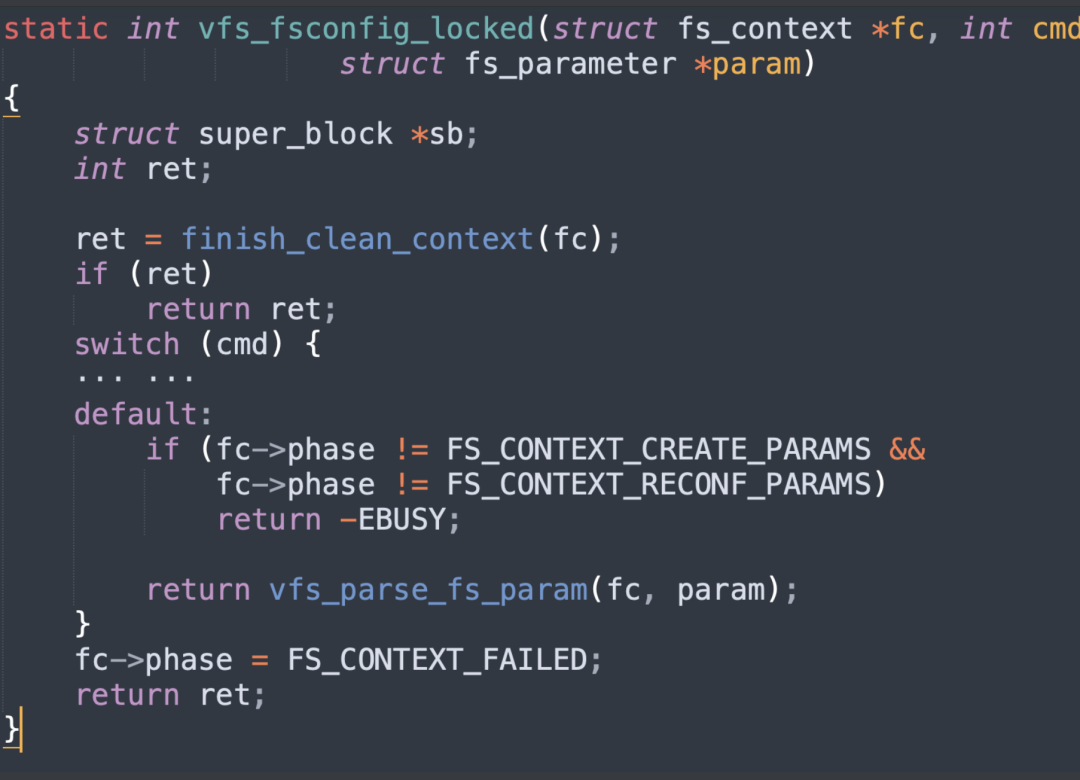
在上图中finish_clean_context函数会调用legacy_init_fs_context 函数来注册回调函数表,该回调函数表中就包括legacy_parse_param`函数,漏洞点就在这个函数。
legacy_parse_param函数所在的漏洞文件为处理文件系统上下文函数的fs_context.c,文件系统上下文的作用是创建superblock用于挂载和重新挂载文件系统,superblock是文件系统最基本的元数据,记录了一个文件系统的特征,比如块和文件大小,以及任何内存块。
https://elixir.bootlin.com/linux/v5.14.21/source/fs/fs_context.c#L525
漏洞函数为legacy_parse_param:
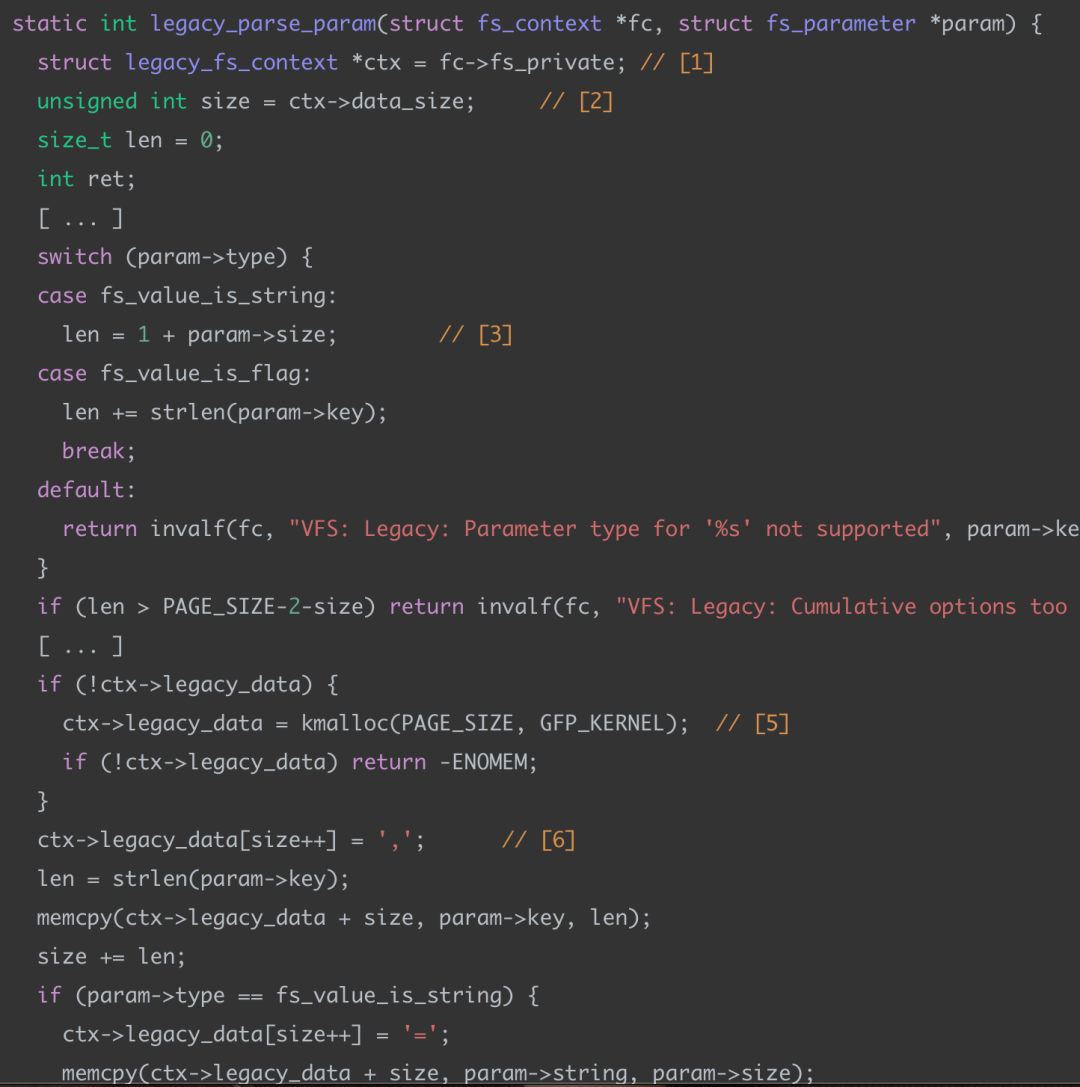
如上代码不需要看懂作用,只需关注漏洞的代码处:

如上这里存在一个长度检查,如果len大于PAGE_SIZE – 2 – size的值,会直接return。
明显这里有问题,判断的类型是size_t,也就是unsigned int,PAGE_SIZE是4096,当size大小为4095或更大时, 无符号减法PAGE_SIZE – 2 – size的计算结果将是一个巨大的正值,发生整数溢出反转,也就是该正值大于len,所以检查将不会触发。
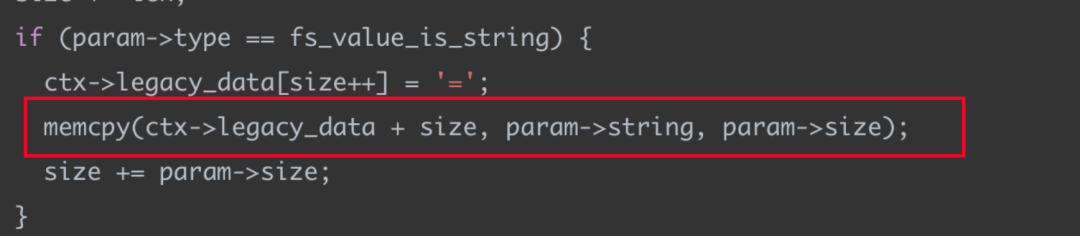
判断输入长度通过后,这里memcpy会将param->string拷贝到ctx->legacy_data的相关操作,如上,而这里拷贝的size是大于PAGE_SIZE - 2的,所以造成拷贝的越界。
调用过程:
fsconfig系统调用入口-->vfs_fsconfig_locked-->finish_clean_context-->legacy_init_fs_context注册回调-->vfs_parse_fs_param-->legacy_parse_param
links
https://www.willsroot.io/2021/08/corctf-2021-fire-of-salvation-writeup.html
http://blog.nsfocus.net/linux-cve-2022-0185/
https://syst3mfailure.io/wall-of-perdition
https://jfrog.com/blog/the-impact-of-cve-2022-0185-linux-kernel-vulnerability-on-popular-kubernetes-engines/
转载请注明来自网盾网络安全培训,本文标题:《容器安全之CVE-2022-0185》
标签:容器安全